
Sessionmentes weboldalak

Az elmúlt hetekben érdekes koncepcióval játszottam. Mi lenne, ha nem lenne munkamenetünk, vagy ismertebb nevén sessionünk? Lehetne-e modern weboldalt készíteni? Működnének-e az elvárt funkciók? Mennyire lenne nehéz fejleszteni?
Miért?
Ezen a ponton joggal gondolkozol el, hogy vajon elgurult-e a gyógyszerem, hogy egy ilyen alapvető technológiát ki akarok dobni? De nézzük, hogy mi is az a session.
A weboldalak a HTTP alapjain nyugszanak. Egy kérés, egy válasz. Ha egy erőforrást el akarunk érni, intézünk egy kérést a szerverhez, amire válaszként megkapunk egy HTML dokumentumot. Vagy egy képet. Vagy egy videót.
A probléma ott van, hogy a szerver nem tudja ezeket a lekérdezéseket egymáshoz kapcsolni. Nem tudja azt, hogy aki az előző lekérdezésben a helyes jelszót küldte, az ugyanaz az ember, aki most a szupertitkos fájlokhoz hozzá szeretne férni.
Na ezt a problémát oldja meg a session. Az első válasszal küldünk a böngészőnek egy sütit, benne egy azonosítóval, amit az innentől minden újabb kéréssel visszaküld. Szerveroldalon ehhez az azonosítóhoz rendeljük azokat az adatokat, amik ahhoz a sessionhöz, ahhoz a munkamenethez tartoznak.
Ez elméletben szép és jó, azonban egy igen csúnya probléma van vele. A programozó.
Az olyan környezetek, mint a PHP ugyanis nemcsak automatizálják a folyamatot, de transzparensen lemezre is szerializálják az azonosítóhoz rendelt adatokat, ami igen kényelmes gyorstárazási lehetőséget kínál, amely ráadásul egy-egy felhasználóra egyedi. Vagyis bejelentkezéskor szépen betöltjük az egész user objektumot, majd eltároljuk a sessionben. És ha már ott tartunk, az összes megrendelését is. És a session fájl csak nő, és nő, és nő.
Amellett, hogy rengeteg helyet foglal a diszken, komoly logikai problémákat is okozhat a sessionök ilyen jellegű használata. Hiszen mi történik, ha a felhasználó egy másik eszközről is bejelentkezik, teszem azt a telefonjáról, és onnan módosítja az adatait?
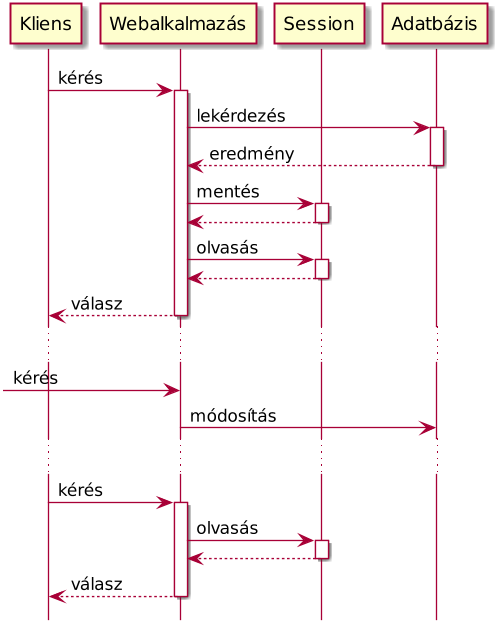
Mindjárt nem lesznek aktuálisak a sessionben gyorstárazott adatok, és mindenféle érdekes problémák lépnek fel, amiket ráadásul nehéz lenyomozni.
Vagy mondok kacifántosabbat. Mi történik akkor, ha egy felhasználó párhuzamosan két lekérdezést indít?
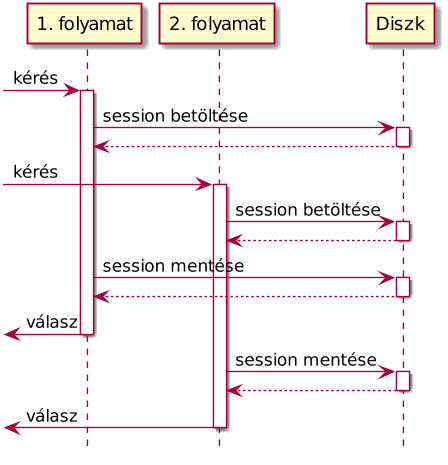
Amint látható, mindkét folyamat betölti a session adatokat, majd mindkettő elkezd dolgozni a saját feladatán. A feldolgozás végeztével mindkettő visszaírja a sessiont a fájlba vagy adatbázisba. Vegyük észre azonban, hogy a második lekérdezés felülírja az első által végzett módosításokat. Például a PHP alapértelmezett munkamenet-kezelője ezt elkerülendő zárolja az adatokat, és egyszerre csak egy folyamatnak biztosít hozzáférést a sessionhöz, ami nem skálázódik túl jól. Egy elosztott rendszeren, ahol a zárolás nem jöhet szóba, az egy az egyben kiolvasott és viszaírt adattömeg folyamatos ütközésekhez fog vezetni.
A sessionökkel önmagában nincs baj. A probléma akkor keletkezik, amikor elkezdjük használni a legtöbb webes környezet által hozzájuk felkínált amorf adattároló zsákot. Vagyis például PHP-ban a $SESSION-t. Nézzük tehát az alternatívákat.
Bejelentkezés
Hogyan valósítanánk meg a felhasználói bejelentkezést sessionök nélkül?
A válaszhoz ihletet merítünk az OAuth protokollból. Amikor a felhasználó bejelentkezik felhasználónévvel és jelszóval, kiadunk egy egyedi azonosítót. Egy tokent. Munkamenet-azonosító helyett ezt tároljuk el a sütiben.
Amikor a felhasználó egy olyan oldalra téved, ahol a felhasználói adataira van szükség, a süti kiolvasásra kerül, és a token alapján betöltjük a felhasználó adatait az adatbázisból.
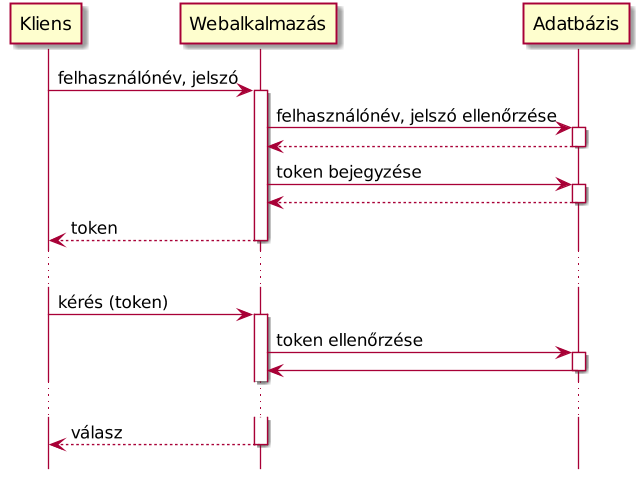
Vagyis minden lekérdezésre kénytelenek vagyunk az auth tokent ellenőrizni. Elsőre azt sejtenénk, hogy ez nagyon nem hatékony, de ha jobban belegondolunk, a sessionöket ugyanúgy be kellett tölteni. Annyi a különbség, hogy most nem egy hatalmas amorf adathalmazt próbálunk kiszedni az adatbázisból, hanem egy nagyonis konkrét céllal nyúlunk hozzá. Az eredmény az, hogy ehhez a célhoz tudunk megfelelő adatbázist választani és optimalizálni.
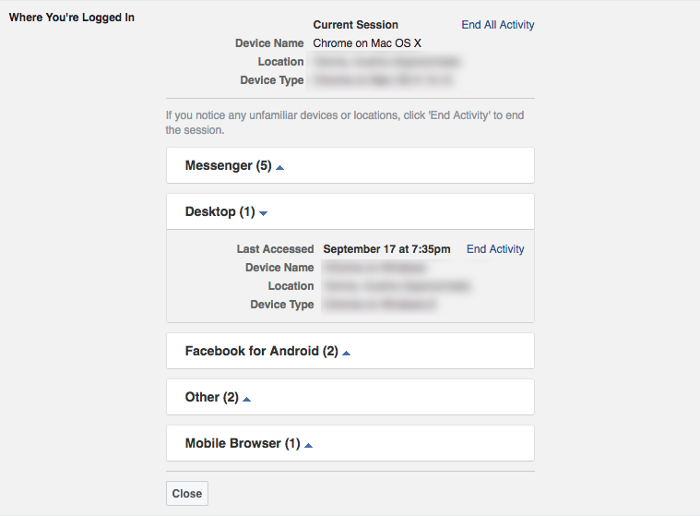
Sőt mi több, mégegy nagyon fontos lehetőség nyílik meg előttünk. Mivel az auth tokeneket a felhasználóhoz kötötten tároljuk, lehetőségünk nyílik a felhasználó aktív tokenjeit kilistázni, hasonlóan mint ahogy a Facebook is csinálja.
Űrlapok kezelése
A sessionök másik gyakori felhasználása a különböző űrlapokba írt értékek megőrzése, például többoldalas űrlapok esetén.
Természetesen erre is van megoldás, hiszen a sessionök helyett minden további nélkül tárolhatjuk sütikben is a felhasználótól kapott adatokat. Gondoljunk bele, semmi olyan nincs benne, amit a felhasználó ne tudna! A böngésző által rendelkezésünkre bocsájtott 4 kB erre bőségesen elegendő. Ha ennél több adatot kell megadni egy űrlapban, akkor egyébként is javasolt egyfajta autosave funkció implementálása.
Állapot megőrzése
Sokan a munkameneteket arra is használják, hogy megőrizzenek bizonyos állapotot. Például azt, hogy melyik lépésnél tartott a felhasználó a regisztrációs folyamatban. Ezt a technikát személy szerint kerülendőnek tartom, hiszen a felhasználó egy vissza gomb megnyomásával semmissé teheti a jól kigondolt állapoti logikánkat.
Helyette azt javaslom, hogy minden lépés rendelkezzen önálló címmel, és egyedileg ellenőrizze, hogy aktuális-e még a kitöltése. Ha nem, automatikusan ugorjon a következőre. Ez megkerüli a session problémáját és a felhasználói élményt is javítja, mert működni fog a vissza gomb.
Ellenérvek
Noha a fenti elképzelést a gyakorlatban is teszteltem, és meglepően jól működik, vannak ellenérvek. A legnagyobb talán az, hogy ezt a fajta működést egyetlen általam ismert űrlapkezelő programkönyvtár sem támogatja. Azaz szinte nulláról kell lefejleszteni mindent, vagy meglehetősen sokat kell módosítani a meglevő szoftvereken.
Ezen felül érdemes figyelemmel kísérni a sütiket tartalmazó fejléc méretét is. Ha sok űrlapunk van, könnyen túlnőheti a webszerveren beállított maximális méretet, ami fura hibákat eredményezhet.
Jelen állapotában ezt a technikát nem tudom javasolni általános felhasználásra. Olyan esetekben mint az enyém, ahol egy egyedi szoftverplatformon kell dolgozni, és esélytelen a külső könyvtárak használata, viszont érdemes megfontolni az alkalmazását.
Összegzés
Ha jobban belegondolunk, ez a megoldás is egyfajta session, amit részben a felhasználói adatok közé, részben pedig a kliensoldalra helyezünk. Csak éppen szépen, strukturáltan tároljuk az adatokat, a jellegüknek megfelelő helyen, nem egyetlen amorf zsákban, amibe az égegyadta világon mindent bele lehet tenni. Ugyanezt az elvet kellene követni a többi adattervezési feladatnál is. Ezzel elérjük azt, hogy az esetleges hibák sokkal lokalizáltabbak, könyebben felderíthetőek, és a teljesítményen is javíthatunk.
■




+1
én mondjuk cookie-ban nem tárolnék form adatokat, sőt leginkább semmit sem, lévén mindig utaznak mindenhova, meg a csrf-re figyelni miatta. ez a token is menjen egy speckó headerben, aztán viszonlátásra. ok, kényelmi szempontból maradhat egy másolat cookieban is, de ne a cookie-ból olvassuk ki szerver oldalon.
adattárolásra meg ott van a javascript, localstorage, meg biztos van más is..
Ez így van
CSRF ellen meg szépen lehet védekezni egy httpOnly CSRF token sütivel.
Süti
Akár
Persze ha a backendet csak API-ként használod, akár a sessionStorage is jó lehet.
Ahol pedig én használok SSO-t
Nekem hiányérzetem van, nem
Nehéz
A cikk mondanivalója inkább az, hogy a session feladatköreit szét kéne szabdalni, apróbb, kezelhetőbb részekre vágni, és ha lehet, a versenyhelyzetektől mentesíteni. (A lockolás az én szememben nem játszik, mert egy bizonyos méret fölött lehetetlen.)
Hát ezzel egyet tudok érteni.
érdeklődés
Nem oldja meg
Azt, hogy OOP kornyezetben ezt hogyan kellene kezelni fel sem merem hozni, mert akkor ez a thread honapokig nem er veget.
Ha kliens oldalon tarolod az
Ütközés?
State
A cel az, hogy ne legyen ilyen jellegu allapotod, hanem pl. a kosar tartalmat ne a sessionben, hanem a DB-ben tarold, userhez kotve. Igy mindket keszuleken ugyanazt latod.
Tehát - ha jól értem - adott
Beépíthetjük közvetlenül a PHP-ba a token kiadását, de annak lefolyása a többi folyamattól független lesz - speciális esetben kell a lockolás, ami nem megfelelő. Van a node.js, amellyel egy socketen keresztül beszélgethetünk.
Mi más van még?
(ui.: hogy vélekednek ma már a CGI-alapú futtatásról?)
Nem
Ránéztem a cikkedre
Hasonló következtetésekre jutottam, mikor a saját OO-alapú blogomat terveztem, de ez sokkal összeszedettebbé rakta eme gondolataimat. A TDD-alapú fejlesztést figyelgettem, de nem nagyon fogott meg. Pedig egy nagyon hasznos dolog: kiszűri a következtethetetlen részeket.
Na, meg is jött a hangulatom egy saját oldal elkészítéséhez! Ezer köszönet! :)
BDD-t nézegessed, szerintem
vitatkoznék :)
Van egy terved (mondom van, nem fejben, hanem le írva :) ), ez alapján írsz egy első tesztet, ami a legelső valamit fogja vizsgálni.
Futtatod.
Hoppá, el szállt, nincs is olyan class. :-D
Hát létre hozod a class valamit.
Megint futtatod.
Hoppá, nincs az a metódus. :)
Csinálsz neki.
...
A mellett, hogy tök mókás, egyrészt duplán figyelsz a kódod minőségére, másrészt a későbbiekben ha változtatni kell, meg véd egy csomó bug lehetőségtől.
Szerintem nem jött át. A
jogos
Ha
Bár koránt sem értek annyira
user_id;
hash('sha512', $data);
// $data = 3-4 adat a kliens gépéről + só, mint pl.: ip, böngésző neve, OS, etc...
// session lopás miatt raktam ezt bele
Ezenkívül minden db-ből érkezik, így az alap problémát kiváltó okok nem merülnek fel nálam.
Session ID
dehogy!!!! Vagy ez vicc volt?
Ez két változó a session-ben.
De miert is?
Es mindez hogyan kapcsolodik ahhoz a problemahoz hogy a session-oknek igen komoly problemaja a lockolas szuksegessege?
Úgy értem a probléma abból
A második megoldást céges inetrneten logó privát rendszerhez használom és elfogadható az esetleges killoggolás.
Nem
1. ha ket lekerdezes jon parhuzamosan, lockolas nelkul elveszhetnek a valtozasok, mert a masodik lekerdezes mentese felulirja az elsot.
2. a session nagyon kinalja magat allapot bevezetesehez. Hogy csak egy trivialis peldat mondjak, sokan az arukosarat a sessionbe rakjak, pedig semmi keresnivaloja nincs ott.
1. Épp ezért tartom
2. Ettől én is kivagyok. Az általam fejlesztett webes alkalmazások akár egy számlázó is, folytatható egy másik gépen ugyanonnan ahol abbahagyta a folyamatot felhasználó.
Ilyet ne
Ilyet nem csinálunk. Volt erről egy izgalmas thread a stackoverflow-n.
A felhasználó azonosítóját tároljuk el max, és ha kell, akkor példányosítjuk a Usert.
Mi akalyoz meg benne?
Kérdések
Lehet választani:
1, írok egy logikát a szerveroldalon, ami megvizsgálja, hogy az adott kérés futtatható-e párhuzamosan, és ez vagy sikerül, vagy pedig nem, az alkalmazás bonyolultságától függően.
2, úgy írom meg a kódot, hogy mindig zárol, és akkor ugyanott vagyok, mint a PHP beépített munkamenetkezelése.
Egy magára valamit is adó vállalatnál nem engedhetik meg maguknak, hogy mindig benn legyünk, és véletlenül érzékeny adatok kikerüljenek, szóval itt nem fontos a felhasználók kényelme.
Valaszok
Hogy valaszoljak a kerdeseidre:
Ez esetben implementalhatsz disk cachelest, de ez egy jol korulhatarolhato feladat, nem kell osszekeverni egy halom mas feladattal.
Marmint ugy erted hogy nalad nem lehet tobb eszkozrol bejelentkezni ugyanarra a weboldalra?
A zarolas a PHP-ban akkor mukodik, ha olyan filerendszeren vagy ami tamogatja a lockolast. Abban a pillanatban hogy pl. lockolas nelkuli NFS-en vagy, vagy atallsz DB alapu session menedzsmentre, azonnal elveszted a lockolast. Tehat abban a pillanatban hogy tulnosz egy szerveren, szembesulni fogsz a problemaval.
1, írok egy logikát a szerveroldalon, ami megvizsgálja, hogy az adott kérés futtatható-e párhuzamosan, és ez vagy sikerül, vagy pedig nem, az alkalmazás bonyolultságától függően.
2, úgy írom meg a kódot, hogy mindig zárol, és akkor ugyanott vagyok, mint a PHP beépített munkamenetkezelése.
Az elsot nem egeszen latom hogy hogyan tudod megvalositani. A PHP architekturaja olyan hogy nem latod azt hogy milyen keresek futnak parhuzamosan. Ha jon egy AJAX request, vagy a favicon.ico hianya veletlenul rafut a PHP fajlodra, maris lehet egy parhuzamos keresed.
Barkit aki egy szervernel tobbon fut.
Alapvetően igazad van,
Nem látok abban problémát, hogy a munkamenetet cache-ként használjam, amíg van elég erőforrás. A mi esetünkben ez akár több megabájtot is jelenthet, ekkora adatmennyiségnek az olvasása-írása ezredmásodpercekben mérhető (az írás úgyis késleltetve történik). Ettől függetlenül elgondolkoztam azon, hogy a statikus részeket (amely a teljes adatmennyiség túlnyomó része) kiteszem egy külön fájlba, így legalább ennek az írását megspóroljuk.
Munkamenet
Lehet sessionoket hasznalni, de nekem az a tapasztalatom, hogy csapatos fejlesztesben mindig elokerul valaki aki nem egeszen erti hogy egesz pontosan hogyna mukodik, es honapokkal kesobb elkezdenek elojonni a versenyhelyzetek es a random 500-as hibak.
Egyebkent ez lazan kapcsolodik.
Párhuzamosság
Ez az egész teljesen irracionális. Teljesen mindegy, hogy tokeneket és/vagy süteményeket használunk, azokat n kérésnél n-szer kell szerveroldalon authentikálni, akár párhuzamos, akár nem. Aztán ez kliensoldalon is bonyolultabb kódhoz vezet, ráadásul, mivel a javascript egy soros nyelv, ígyis-úgyis csak egymás után tudod ezeket az adatokat megjeleníteni, azaz pontosan ott vagy, ahol a part szakad.
Ezzel szemben, ha egy kérés megy el, ami minden adatot összeszed, és azokat egyszerre adja vissza, azonnal spóroltál a betöltési időn és a kliensoldal is egyszerűbb lesz.
Tehát ha a párhuzamosság mind a szerver-, mind pedig a kliensoldalon csak problémákat okoz, akkor minek erőltetni? Én teljességgel ellene vagyok, a felhasználó is maradjon nyugton, ne kattintgasson addig össze-vissza, amíg az adott tranzakció el nem készült, főleg, ha pénzügyekről van szó. Én a magam részéről már SJAX-ot használok mindenhol.
Úgyhogy szerintem nagyon is hasznos a zárolás miatt a munkamenet, legalább nem nekem kell leprogramoznom, hanem megcsinálták és kitesztelték helyettem.
Igen
Ami a lockolast illeti, ez rendben lenne, ha a PHP session doksi nem promotalna orrba-szajba hogy milyen jo SQL/Memcache/stb backendet hasznalni sessionokre. Mindossze ezen az oldalon irjak emlites szintjen a zarolast. Azt sehol nem irja (FIXME) hogy ha nem a default file-alapu session handlert, akkor bizony nem kapsz lockolast. Kulonos keppen nem a custom session handlers doksiban.
Szoval ha Te egy szerveren boldog vagy a sessionokkel, akkor hajra, csak ha egyszer egy alkalmazasod tulno ezen, akkor gondolj vissza erre a threadre.
Több szerver
Mondom, alapvetően jót írsz, és ennek hatására én például biztosan fogok egy-két dolgot változtatni, de amire az érveket hozod, én azt nem látom olyan nagy problémának - aztán majd kiderül.
Zárolás
A fenti cikkedben te sem említed közvetlenül, hogy a tokenes megoldással a zárolást magunknak kellmegoldani, márpedig anélkül lyukra szaladhat az egyszeri programozó. A szövegből pedig csak közvetve derül ki, hogy ez az egész szimbólumos varázslás leginkább több szerveres környezetben érdekes:
Inkabb
$SESSIONvaltozon keresztul szolitottak meg, hogy meg veletlenul se lehessen elfedni a logikat.Nekem ez a bajom az egesszel: van egy hatalmas zsakod ami azt igeri hogy tomb tarolast biztosit tobb requesten keresztul. A fejleszto nincs rakenyszeritve hogy elgondolkozzon azon, hogy ez hol fogja arcon vagni.
Vajon megoldható, hogy
Meg
Jatsszunk el a gondolattal: van egy egyedi azonosito, amit szerver oldalon is tarolunk. Ha ugy tartja kedvunk, akkor ehhez adatokat is kothetunk. Ezek jellemzoen a kovetkezo kategoriakba esnek:
1. felhasznalo azonositas
2. urlapok tartalma es az ehhez kapcsolodo hibauzenetek
3. felugro uzenetek oldalvaltasok kozott (flash messagek)
4. allapotok (pl. arukosar)
5. session-level cache
Felhasznalo azonositas
Ha a felhasznalo bejelentkezik, hozzakotjuk a felhasznalo objektumat a sessionhoz vagy tokenhez. Ha kijelentkezik, toroljuk. Igen am, de itt erdemes arra figyelni, hogy a biztonsagi best practicek azt javasoljak, hogy valtoztasd meg a session azonositot be- es kilepeskor. Vagyis itt mar serul az, hogy a munkamenettol fuggetlen a mukodes.
Nekem jobban bejott az a modszer, hogy belepeskor a felhasznalo kap egy auth tokent es az sutiben tarolodik. Minden olyan muvelet amihez felhasznaloi azonositas kell, csak auth token kisereteben vegezheto el.
Urlapok tartalma
Itt gyakorlatilag egy POST lekeresnel szerializaljuk az urlap tartalmat (PHP szerializacio, JSON, stb) es a kovetkezo GET lekeresnel elohivjuk.
Ez megint egy olyan dolog, amit akar kothetunk sessionhoz ha ugy tartja kedvunk, de tokeletesen felesleges szerver oldalon foglalni a helyet. Egy atlagos urlap tok szepen elfer sutiben kodolva. Nyilvan itt PHP szerializaciot hasznalni ongyilkossag, de a JSON + Base64 nekem tokeletesen bejott.
Biztonsagi szempontbol nem bir relevanciaval, mert ugyis visszakuldjuk a felhasznalonak az adatokat.
Felugro uzenetek
Itt kicsit kacifantos lesz a sztori, mert ha magat a szoveget taroljuk el, akkor sajat magat meg-XSS-ezheti a user. Tekintettel arra hogy az uzenetek tarolasa szinten nem biztonsagi kerdes, az uzenet helyett atadhatunk viszont egy forditasi (translation) kulcsot sutiben, ami megoldja a problemat.
Allapotok (pl. arukosar)
Ezek a fajta adatok a legritkabb esetben tartoznak szorosan a munkamenethez, sokkal inkabb a felhasznalohoz kothetoek. Mivel a legtobb ember mostanaban mar tobb keszuleken utazik (tablet, laptop, mobil) celszeru lehet ezt inkabb adatbazisban tarolni es a felhasznalohoz kotni munkamenet helyett.
Ha nagyon munkamenethez kell kotni, en itt praktikusnak erzem kiadni pl. egy kosar azonositot. Ez lehetove tesz olyan huncutsagokat is, hogy pl. elkuld egy linket a kosarhoz a masik keszulekre ha nincs belepve.
Session-level cache
Na itt utkozunk eloszor problemaba. Eloszor is, ennek szerver oldalon kell laknia. Masodszor komoly versenyhelyzetek lephetnek fel. Ha pl. eltaroljuk a felhasznalot, akkor a permissionjei csak a kovetkezo belepeskor valtoznak, ami a "maradj bejelentkezve" opcio hasznalataval igen sokara lehet. (Vagyis belefutsz a stale cache problemaba.)
Mivel en eloszotott rendszereken dolgozom, nekem a session-level cache nem opcio, inkabb optimalizalom kicsit a queryjeimet. Ha pedig statikus adatokrol van szo (pl. elerheto dijcsomagok), akkor az alkalmazasom indulasakor elinditok egy kulon threadet ami 15 percenkent lefrissiti az adatokat memoriaba. (Ezt PHP-ban is meg tudod csinalni, csak cronjobot kell irni ami Memcachebe vagy fileba betolja a frissitett adattartalmat.)
Kihagytam valamit?
Kliens
Amivel egyáltalán nem értek egyet, az az, hogy kliensoldalon bármilyen adatot vagy üzleti logikát tároljunk, több okból is:
Peter-Paul Koch blogján olvastam valahol azt a találó definíciót, hogy a kliensoldal, azaz a böngésző undefined, azaz csak találgathatsz arról, mire képes és mire nem, mennyi erőforrással rendelkezik. Ebből következik, hogy mindent, amit csak lehet, szerveroldalon kell megoldani, mert az a biztos pont az egész kommunikációs láncban:
- az egyszerűbb kliensoldali logika miatt jóval kevesebbszer kell az ottani kódhoz nyúlni, azaz olcsóbb a karbantartása
- ugyanemiatt jóval kevesebb a hibák száma
- a rosszul megírt, lassú javascript nem meríti le a mobil eszköz akkumulátorát
- pont az általad említett esetekben, amikor egy felhasználó több eszközről venné igénybe a rendszert, a kliensoldalon tárolt alkalmazásadatok egy készülékhez kötik az adott funkciót
- ha megnézzük a weboldalak forrását, működését, kezdve a legnagyobbaktól: Youtube, Facebook, Microsoft – akiket mindenki másol –, egyértelműen kiderül, hogy a frontendesek túlnyomó többsége (99,9%-a) dilettáns, akik idő és tudás hiányában képtelenek jó minőségű kódot kiadni a kezükből; hogy mégis van munkájuk, az annak köszönhető, hogy a szakmában lévő elképesztő munkaerőhiány miatt nincs igazán versenyhelyzet
Éppen ezért én csak és kizárólag a lehető legbutább és legprimitívebb kliensben hiszek, ami lehetőleg JS nélkül is működik (SPA-k esetében pedig csak a megjelenítés a feladata), hisz ez a technológia a legnagyobb biztonsági rés az egész web történetében.Vapici
Sütemény
Persze attól függ, hogy ezeket az adatokat hogyan írod a html-be, ha kliensoldalon, akkor az már egy hibaforrás.
En is
Már indokoltad
Ha nagyon munkamenethez kell kotni, en itt praktikusnak erzem kiadni pl. egy kosar azonositot. Ez lehetove tesz olyan huncutsagokat is, hogy pl. elkuld egy linket a kosarhoz a masik keszulekre ha nincs belepve.
Szerintem félreértetted, amit
A js jó kliens oldalon, ha van b terv arra az esetre, ha letiltaná a felhasználó. A keretrendszerek elfedik a böngészők közötti különbségek nagy részét, úgyhogy általában nem kell ilyesmivel foglalkozni, ha használsz valamilyen keretrendszert. Vanilla js-t polyfillekkel kombinációban van értelme használni szerintem, vagy esetleg ha zárt csoportnak fejlesztesz, akikről biztosan tudod, hogy milyen böngészőt fognak használni.
szerk:
Abban igazad van, hogy külön kell választani ezeket a fajta adatokat aszerint, hogy mi az, aminek szinkronban kell lennie eltérő klienseket (akár egyszerre) használva, és mi az, aminek nem. Az előbbi resource state, és a szerveren kell menedzselni nem sessionben, hanem az adatbázisban, az utóbbi client state, és jobb ha a kliensben marad mondjuk cookie-ban, token-ben, js-ben, vagy bármi egyéb módon.
Zárolás
Nyilvan
Mivel en eloszotott
Viszont két különböző dolog keveredik itt szerintem a hozzászólásokban, ami nincs eléggé kiemelve. Egyrészt szükséges a repository atomikus hozzáférésének biztosítása (akár http session, akár más), de ennél kevésbé triviális, hogy az üzleti logika mennyire és hol van kitéve race condition lehetőségének. Egy olyan megoldás, ami egy egész request feldolgozás idejére rádob egy exclusive lockot, sorosítani fogja a requestek feldolgozását, legyen szó író, vagy olvasó requestekről. Itt ha jól értem, akkor a cikk erre a problémára van felhúzva. Ami tehát nem mindegy:
- lockolás granularitása (pl a baromi drága validációnak semmi helye egy critical sectionben)
- lockolás módja (pl exclusive vs read/write lock, pessimistic vs optimistic lock)
Nagyobb teljesítményű, skálázhatóságra tervezett rendszereknél olyan megoldást kell választani, ahol ezek a választási lehetőségek fennállnak. Egyértelmű, hogy itt a php sessionje már nem elfogadható megoldás.
Érdemes még megemlíteni, hogy ha architecturálisan megoldható, single writer alkalmazásával akár teljesen el is hagyható a lockolás és csak az atomicitást kell tudni biztosítani, a readereknek nem kell várakozniuk a writerre és viszont. Ez már persze messze nem triviális, pl a single writer node(ok) el is halálozhat(nak). A lényeg, hogy vannak opciók a concurrency és a skálázhatóság kezelésére. De megfelelő tapasztalat híján a vége garantáltan fejvakarás lesz.
Azt hiszem concurrency
yesplease
Biztos?
Nagyon érdekes téma, de eléggé bele kell nyúlni a meglévő programba a használatához, és nem biztos, hogy ez a felület a legalkalmasabb arra, hogy egy jó és biztonságos alapkód elkészítéséhez.
PHP
PHP
OK
+1, remélem nyelv mentes
Gondoltam már rá
Ha esetleg van még pár téma felajánlás, akkor az én kedvem is még nagyobb lesz cikket írni... ;)
Szerintem teljesen mindegy a
Mindenkeppen
Web
Alapovetoen
Egyebkent meglepo, de pl. banki rendszerek sem feltetlenul mukodnek zarolassal, ezert tudsz minuszba menni a szamladdal akkor is ha nincs beallitva hitelkeret. Egy kis webshopnal ez nyilvan nem opcio, ott egy 10e Ft-os hiany is nagyon faj, de pl. Amazon meretekben mar egeszen mas a teszta. Ezen a ponton ez masszivan uzleti dontes, nem technologiai.
Cikket irnek rola, de attol tartok hogy ahhoz elobb erosen utana kene olvasni az elmeletnek mert elegge "gyakorlat-szagu" a tudasom. (Tuti belem lehet kotni jo sok helyen hogy az nem is ugy van.)
+1, én is úgy tudom, hogy
JMX
Mi egyébként speciel monitorozásra pont nem használjuk a JMX-et. Prod supporthoz vezettünk ki rá funkcionalitást, amivel bele tudnak nyúlni dolgokba, ha issue van.
Egyelőre concurrencyről kezdtem el rendszerezni a gondolataimat. De sör méréshez más indokot találjunk. Sör, meg a concurrency nem barátok :)
Java
Proghun volt egy hasonló
Melyik lib csinálja amúgy?
Koszi!
A container memory használata
Eszembe jutott még egy cikk: Why does my Java process consume more memory than Xmx?
Illetve plumbréknek van egy GC handbookja, ez szerintem egyértelműen must read.