
A NoSQL világa – 1. rész: Bevezető

Az SQL nyelv fejlesztése az 1970-es évek elején az IBM-nél kezdődött. Ezzel egy időben készültek el az első relációs adatbázisok (RDBMS). Az SQL kidolgozásánál elsődleges szempont volt az egyszerűség megőrzése azzal együtt, hogy rendkívül komplex lehetőséget nyújtson az adatok hozzáféréséhez. Az SQL és RDBMS rendszerek kéz a kézben fejlődtek az elmúlt 40 évben. Hatalmas adatmennyiséget kezelünk ezekkel a rendszerekkel, nagyon sokáig svájci bicska-szerűen mindenre megoldást kínáltak. Kialakultak az informatika szegmenseihez idomuló megoldások, így amikor a web elterjedt, vele együtt lettek népszerűek az egyszerűbb RDBMS rendszerek, mint a MySQL vagy a PostgreSQL.
„NOSQL technológiák és alkalmazásuk” c. szakdolgozatom alapján egy többrészes értekezésem első részét publikálom. Témája egy új, feltörekvő szegmense az informatikának, aminek jelenleg kevés a magyar szakirodalma. A cikk sorozat egyes részeiben a NOSQL technológiákat mutatom be részletesen, gyakorlatias megközelítéssel. Első ízben az alapvető fogalmi kérdéseket tárgyalom. Fontos megemlítenem, hogy dolgozatom megírását az Adverticum Zrt. emberi és hardveres erőforrásokkal egyaránt támogatta.
A weben megjelenő alkalmazások új kihívások elé állították az RDBMS rendszereket: hatalmas adatmennyiségből a másodperc tört része alatt kell eredményeket produkálniuk. Sokáig nem mutatkoztak a gyengeségeik. A kilencvenes évek végén az internet robbanásszerű elterjedésével azonban néhány cégen belül hatalmas adattömegek gyűltek össze. Ekkor ütköztek falba az ezeket a rendszereket építő fejlesztők, ami arra kényszerítette őket, hogy új típusú adattárolási és adatfeldolgozási eljárásokat fejlesszenek. Először az internetes keresők (pl. Google, Yahoo) kezdtek kutatásba az új lehetőségek iránt, később a közösségi hálózatok elterjedésével az ezeket fejlesztő cégek is hasonló problémák okán indították el az RDBMS rendszerek cseréjének folyamatát. A kétezres évek közepére a folyamat az új típusú rendszerek publikálásával felgyorsult. A Google nyilvánosság elé tárta több belső szoftverének specifikációját, ezután pedig beindultak azok a projektek, melyek ezeket szerették volna lemásolni.
2009-re ezek a fejlesztések beértek, és hónapról hónapra jelentették be nagy cégek az adataik migrálását az új tárolókra. Általánosságban elmondható, hogy a fejlesztések ebben az évben érték el azt a stabilitást, amikor kritikus rendszereket lehetett rájuk építeni. Az egyre szaporodó cégek ezen projektek körül továbbgerjesztették a fejlesztési folyamatot. Érdemes megjegyezni, hogy az Apache Alapítvány nagy szerepet vállalt a szoftverek fejlesztési hátterének biztosítására. Több terméket is (Hadoop, Cassandra, Thrift stb.) kiemelt projektté nyilvánítottak, mellyel jelezték és egyúttal biztosították, hogy a későbbiekben sem fog leállni a fejlesztésük.
Eric Brewer CAP tétele
Térjünk át egy fontos elméleti pontjára az adatbázisoknak. A tételt először Eric Brewer fogalmazta, miután több skálázhatósági problémával találkozott különböző rendszereken.
A tétel kimondja, hogy egy elosztott rendszer nem képes egyszerre teljesíteni a
- konzisztencia,
- hozzáférhetőség (availability) és a
- partíció tolerancia
által támaszott követelményeket.
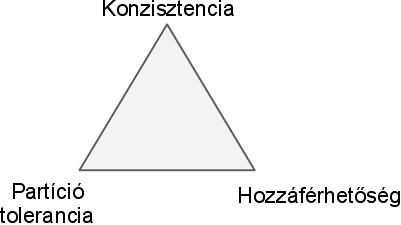
CAP háromszög
A konzisztencia fogalma az elosztott tárolók mint rendszerek esetén azt jelenti, hogy a tároló egy változást egyik pillanatról a másikra hajt végre. Nem történhet olyan eset, hogy a rendszer egyes elemei különböző válaszokat szolgáltatnak a klienseknek. Példaként,adott egy 2 csomópontból (A, B) álló adatbázis hálózat, amelynek minden pontja elérhető a kliens számára. A kliensek bármely csomóponton keresztül módosíthatják és olvashatják az adatbázist. Ha A csomópontban változás történik egy adatsoron, annak a változás pillanatában meg kell jelennie a B csomóponton is. Tehát az adatbázis állapotváltozásai csak egyszerre történhetnek a csomópontokon, ezért a csomópontoknak szinkron működésűnek kell lenniük. A szinkronizációban több helyen is előfordulhatnak problémák, ezeket az adatbázis rendszerek más-más stratégiával védik ki. Csak akkor nevezhető egy adatbázis konzisztens rendszernek, ha bármely csomópontjából bármely időpontban ugyanazon információt kapja vissza a kliens. A konzisztencia különösen a kritikus rendszereknél fontos. Ezek például a bankok, repülőterek és minden olyan rendszer, ahol hibákat okozhat az inkonzisztens adat megjelenése. A NOSQL adatbázisoknál gyengébb elvárások jelentek meg a konzisztencia felé. Az ezeket az adatbázisokat használó rendszereknél gyakran nem okoz problémát, ha egy adatsor nem a legfrissebb változatát kapja vissza a kliens.
A hozzáférhetőség vagy magas rendelkezésre állás kérdése a tétel második sarokpontja. A rendelkezésre állás százalékban kifejezhető érték, amely megmutatja hogy az adott rendszer X időtartamból mekkora Y időtartamban tudott válaszokat szolgáltatni, azaz volt elérhető. A legsebezhetőbb az egy csomópontot tartalmazó rendszer, mert az adatok 100%-a eltűnik a csomópont kiesése esetén. Több csomópont esetén a hozzáférhetőség mérése bonyolultabbá válik. Ezekben az esetekben elképzelhető, hogy a rendszer nagy része elérhető, de a benne található egyes csomópontok kiesése miatt a teljes adattartalmat még sem tudja elérni a kliens.
A partíció tolerancia akkor merül fel egy rendszernél, amikor az azt alkotó csomópontok közötti hálózatban hiba keletkezik, vagy megszűnik a kapcsolat. Ekkor az adatbázis két különálló hálózatra szakad. A rendszer ekkor választás elé kerül: folytathatja a működését, vagy leáll. A két hálózat ilyenkor nem tud egymás működéséről, teljesen függetlenül változnak a kapcsolat megszakadása után. Amikor a hiba megszűnik, és a két hálózat újra egyesül, a rendszernek képesnek kell lennie az adatokat szinkronba hozni, hogy megszakítás nélkül folytatható legyen az adatbázis működése.
A tételből következően egy tároló csak kettő tulajdonságot valósíthat meg a háromból. Ez alapján különböztetjük meg a tárolók 3 fő csoportját:
- CA (Consistency + Availability): A konzisztenciát és a hozzáférhetőséget tartják szem előtt ezek a rendszerek, a hálózat szétesése esetén működésképtelenné válnak. Eszerint működő rendszerek: MySQL, PostgreSQL, Vertica
- AP (Availability + Partition tolerance): Ezek a rendszerek a lehetőségekhez képest mindig elérhetőek, és jól működnek a hálózat szétesése esetén is, cserébe feladják a konzisztens működést. Ilyenek például: Cassandra, SimpleDB, CouchDB, Riak, Tokio Cabinet
- CP (Consistency + Partition tolarence): Konzisztens működés várható el ezektől a rendszerektől, és a hálózat elválása esetén is működnek, de cserébe romlik a hozzáférhetőség. A következő rendszereket lehet ide sorolni: Bigtable, HBase, MongoDB, Redis, Scalaris
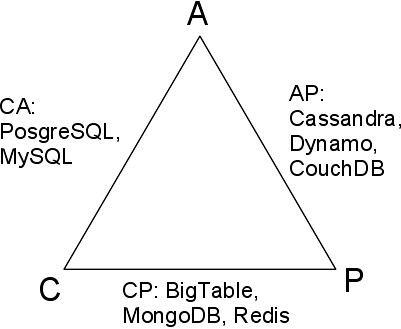
A tárolók elhelyezkedése a CAP háromszögön
A NOSQL
Miért NOSQL? Kezdetben a NoSQL (kis o betűvel) betűszó használata volt jellemző. Ez az SQL-től teljesen eltérő nyelven és interfészen elérhető adattárolókat takart. 2010-ben a NOT ONLY SQL elnevezés használata nyert egyre nagyobb teret az új generációs adattárolási rendszerekre utalva. Én is találóbbnak tartom ez utóbbi elnevezést, mert léteznek olyan rendszerek, amelyeknél lekérdezőnyelvnek az SQL-hez nagyon hasonló nyelvet implementáltak. Ilyen például a GQL#, melyet a Google App Engine rendszerén keresztül bárki elérhet.
A tárolók csoportosítása
Jelenleg 4 főbb csoportját lehet elkülöníteni a tárolóknak. Ezek főleg az adatstruktúra kezelésében és a CAP tételből eredően más-más kitűzött célban térnek el egymástól. Ez a felosztás azonban már egyre felületesebb, havonta egy-egy új kategória jelenik meg. Jól példázza a szegregálódást, hogy a nosql-database.org-on a kezdeti négy kategóriából már tíz lett.
Kulcs/érték tárolók (Key/Value stores)
A kulcs/érték tárolók a legegyszerűbb tárolók a négy típusból. Ennél az adatmodellnél az adott információt tartalmazó adatrekeszt egy kulcs segítségével lehet elérni. A kulcsot a felhasználó maga választhatja meg, esetleg a tárolóra is bízhatja annak generálását.
A tipikus kulcs/érték tárolók string kulcsokkal és string értékekkel dolgoznak, melyeket byte tömbökké alakítanak. Az értékek általában binárisan biztonságosan (binary safe) tárolódnak, így lehetőség nyílik sorosított (szerializált) objektumok vagy bináris fájlok tárolására is.
Ezek a tárolók gyakran az adatok nagy részét – vagy egészét – a memóriában tartják, ezzel gyorsítják a kiszolgálást. A cache rendszerektől (pl. Memcached) azonban ezeket az különbözteti meg, hogy az adatokat valamilyen nem illékony tárolón is lementik annak érdekében, hogy egy esetleges nem várt esemény (pl. áramszünet) után is vissza tudják állítani azokat.
A jelentősebb tárolók ebben a típusban: Amazon SimpleDB, Microsoft Azure Table Storage, Redis, Tokio Cabinet, Scalien Keyspace (magyar fejlesztés), Berkley DB, MemcacheDB
Dokumentum tárolók (Document stores)
Erre a típusra is jellemző, hogy az adatokat valamilyen hash alapján tárolja az adatbázis, de magának a letárolt adatnak van szerkezete, azaz az adatbázis képes az adatstruktúra alapján kereséseket és gyűjtéseket végezni. Tehát nem lehet csak egyszerűen egy továbbfejlesztett kulcs/érték tárolóként gondolni ezekre a rendszerekre. A fejlesztésük mozgatórugója az, hogy a fejlesztők gyakran az adatbázisokban dokumentumokat tárolnak, melyeket sokszor csak egy kulccsal (elsődleges kulcs) érnek el. Sőt a válaszidőt gyorsítandó eltérnek az adatbázis normalizálástól, és redundanciákat vezetnek be az adattárolási struktúrában. Ezeket a rendszereket valószínűleg sokkal jobban ki tudja szolgálni egy dokumentum tároló.
A dokumentum tárolók legnépszerűbb adatstruktúra leíró nyelve a JSON, ami egy ember számára értelmezhető, a számítógépeknek pedig könnyen feldolgozható struktúrát biztosít.
A jelentősebb dokumentum tárolók: CouchDB, MongoDB
Bigtable implementációk vagy „oszloptárolók” (Bigtable implementations, Column stores)
A Google 2006-ban publikálta a legtöbb szolgáltatásához használt Bigtable adattároló specifikációját. Ebben kellő részletességgel leírták, hogy milyen módon valósították meg a hatalmasra nőtt adatbázisainak tárolását. Több fejlesztés is megindult, hogy a specifikációban leírt tárolóhoz hasonló alkalmazásokat dolgozzanak ki. Ezek közül számos nyílt forráskódú, elérhető mindenki számára.
Az RDBMS rendszerek egy táblában a sorokat egymás után tárolják. Ha csak egy mezőre van szüksége a kliens alkalmazásnak, először a sort keresik ki, majd a sorban a megfelelő oszlopot. Ettől eltérően az oszlopokat szétbontva is lehet szervezni a tároló rendszert. Ez az alapja az oszloptároló rendszereknek.
Gyakori igény az adatok különböző verzióinak megőrzése. Ezt általában ezek a rendszerek egy új dimenzió bevezetésével, a verzióval valósítják meg.
Példa implementációk: Hadoop, Cassandra
Gráftárolók (Graph stores)
A kétezres években megjelenő „web 2” új kihívások elé állította azokat a fejlesztőknek, akik szociális hálókkal vagy webkettes portálokkal foglalkoztak. Hatalmas és mély hálózatokat, gráfokat kell egy-egy portálnak kezelnie, és azokból kimutatásokat készítenie. Elég, ha a közösségi portálok egyik alap funkciójára, a közös ismerősök megtalálására gondolunk. Erre az RDBMS adatbázisok igen gyenge megoldást kínálnak, mivel sokszor többszörös JOIN-okkal kell egy-egy információt kinyerni. Természetesnek tűnik tehát, hogy valamilyen más módszerrel tárolják le ezeket az adatokat. Erre a gondolatra épülve fejlődtek ki a gráf tárolók, melyek a gráfok feldolgozása során felmerülő nehézségeket szeretnék megkönnyíteni.
A közösségi hálók után a második felhasználási területe az ilyen típusú tárolóknak a szemantikus web. A W3C az RDF ajánlással kíván egy olyan nyelvet a felhasználók kezébe adni, amivel az egyszerű adatokból strukturált információvá alakítható a web. Az adatobjektumok közötti hivatkozások tárolásához az egyik legjobb lehetőség a gráf tárolók alkalmazása.
Jelentősebb tárolók a kategóriában: Neo4J, InfoGrid
■




Úgy tűnik egy újabb nagyszerű
Grat
Folyt
Köszi
Persze várom a folytatást is.
Tetszett!
Szakdolgozatomhoz segítség
Most írom a szakdolgozatom az Óbudai Egyetemen és szeretném megkérdezni, hogy a te szakdolgozatodból küldenél-e nekem olyan részeket, amely alapján össze tudok rakni egy NOSQL adatbázist az elkészítendő oldalomhoz.
Várom válaszod, és előre is köszönöm segítséged!
Ha segítenél, akkor megírom az email címemet is!
seven databases in seven
egész jó könyv, pont erről szól...