
Aszinkron JavaScript programozás

A cikkben a JavaScript egyik misztikus jószágát, az aszinkron programozási lehetőségeket járom körbe, és próbálok a felmerült problémákra minél több, minél egyszerűbb programozási megoldást keresni.
Az olvasó részéről a cikk feltételezi, hogy tisztában van a JavaScript nyelv szintaktikai sajátosságaival, magabiztosan mozog a környezetben. A bemutatott módszerek példakódjainál nem a robusztusságot helyeztem előtérbe, inkább proof of concept jellegű megoldásoknak szánom őket, ebből következően többnyire nem teljesek, nem optimálisak, pusztán egy-egy minta vázlataként szolgálnak.
Event loop
A JavaScript alapvetően egyszálú környezetben fut, az alkalmazásunk szempontjából azonban fontos, hogy reszponzív maradjon. Mit is jelent ez?
A JavaScript esemény alapú modellben gondolkozik. A koncepció nem új, gyakorlatilag az összes grafikus alkalmazás ugyanezen az elven működik. Csak hogy egy példát említsek: ha írtunk már programot nyersen a WinAPI segítségével, akkor is pontosan ugyanezt a modellt használtuk:
MSG message;
while (GetMessage(&message, 0, 0, 0)) {
TranslateMessage(&message);
DispatchMessage(&message);
}Ez volt az alkalmazás lelke. A program ugyanúgy egyszálú volt, az események (MSG struktúra) pedig egy végtelen ciklusban (ez az event loop, eseménykezelő hurok) kerültek feldolgozásra. A trükköt a GetMessage() végzi, egy olyan rendszerhívás, ami az alkalmazás eseménysorából kiveszi a soron következő eseményt, illetve ha nincs, akkor vár (a CPU pörgetése, terhelése nélkül). Az eseménysor egy egyszerű FIFO adatszerkezet, semmi bonyolult.
Ha az eseménykezelő valamilyen hosszadalmas dolgot csinált (pl. while (1);), akkor a program lefagyott, hiszen nem tudta feldolgozni a többi eseményt (kattintás a bezárás ikonra stb.), a végtelen ciklus miatt sosem jutott vissza a hurok elejére.
A JavaScript teljesen hasonlóan működik. Maga a ciklusmag el van rejtve előlünk (és nem is érdekel minket, hogy hogyan van megvalósítva), viszont megfelelően „okos” eseménykezelővel szintén le tudjuk fagyasztani a böngészőt vagy az aktuális böngészőfület (ez a böngésző architektúrájától függ leginkább, manapság az a tendencia, hogy minden fül saját folyamatban fut, de mindenképpen saját szálon):
document.body.onclick = function () {
while (1);
}Egészen addig, amíg nem kattintunk, semmi sem történik, utána viszont leblokkol a UI (user interface, felhasználói felület) szála, melyen a JavaScript eseménykezelőnk is fut. A függvényünk soha nem tér vissza, így nem engedi, hogy bármi más futhasson.
Synchronous JavaScript And XML
Vegyünk egy kevésbé irreális példát, az (ilyen néven nem igazán használatos) SJAX-ot (Synchronous JavaScript And XML), ami rendelkezzen egy egyszerű API-val. Egy gombra kattintás után szeretnénk, ha letöltene egy erőforrást az internetről, és az eredményt elhelyezné az oldalon:
button.onclick = function () {
/**
* A /hello címen található webszolgáltatás
* a 'Hello {name}!' sztringet adja vissza
*/
var result = SJAX.get('/hello?name=' + name);
resultBox.innerHTML = result;
}Sajnos az SJAX hívásunk blokkolni fog, hiszen amíg nem épült föl a TCP kapcsolat, nem kerültek elküldésre a HTTP fejlécek, nem dolgozta fel a kérést a távoli szolgáltatás, és nem küldte vissza az eredményt, addig nem tudunk más eseményt feldolgozni. Mivel gyakorlatilag minden interakció esemény, az alkalmazás fagyott ezen időtartam alatt. Ha a csillagok megfelelően állnak, akkor persze ez nagyon rövid időintervallum (néhányszor 10 ms), de ha épp nem optimális a hálózat, akkor ez akár másodpercekig is eltarthat. Ez a felhasználói élmény szempontjából roppant előnytelen.
Asynchronous JavaScript And XML
Az igény tehát adott: szeretnénk, ha az ilyen hívásaink aszinkron jellegűek lennének. Fohászaink meghallgattattak, jelenleg széleskörűen elérhető a böngészőkben az XMLHttpRequest objektum, amit pontosan erre találtak ki (ez képes a szinkron kommunikációra is, de az imént tárgyalt hátránya miatt nem javallott a használata). Vegyünk ismét egy egyszerű példát, most AJAX-ra, egyszerűsített API-val:
button.onclick = function () {
AJAX.get('/hello?name=' + name, function (result) {
resultBox.innerHTML = result;
});
}Mi is történt itt? Az AJAX.get() azonnal visszatér, azaz az események feldolgozása tovább folyhat. Viszont regisztrálunk egy eseménykezelőt, ami akkor fog lefutni, amikor megkaptuk a hívás eredményét. Hasonlítsuk össze a két megoldást! A különbséget akkor értjük meg igazán, ha a szekvenciadiagramjukat megnézzük (jelölésben próbáltam az UML szabványhoz ragaszkodni, az objektumok/metódusok neve teljesen ad hoc jellegű, leginkább a könnyebb megértést szolgálja):
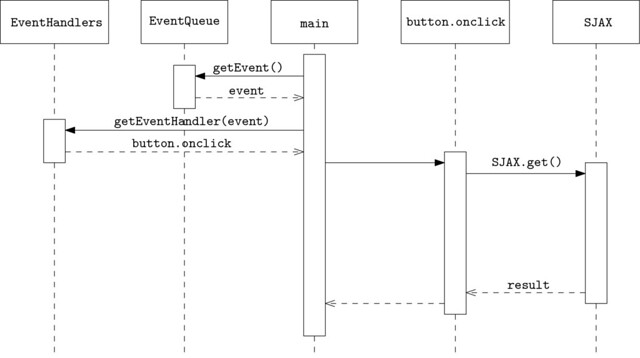
A szinkron működés miatt az eseménykezelő ciklusnak esélye sincs a futásra, tehát blokkolni fog.
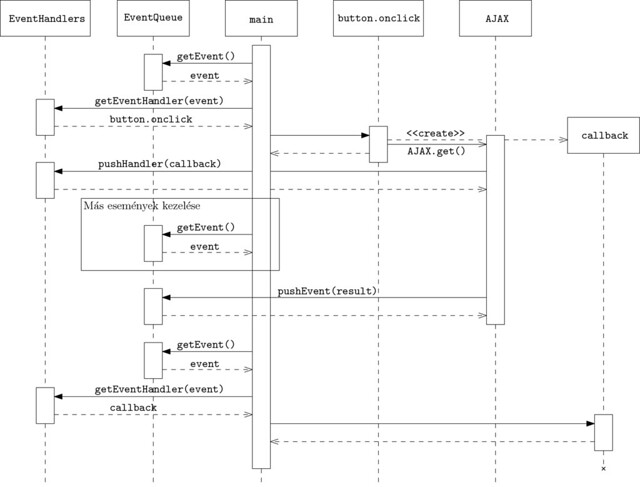
Ez viszont trükkös! Az AJAX.get() hívás aszinkron, azaz a futás jogát visszaadja a hívó félnek (csak néhány olyan járulékos dolgot tesz, ami szükséges, ilyen például az eseménykezelő callback függvényünk regisztrálása). Az eseménykezelő ciklusunk tehát futhat, a felület nincs blokkolva.
Amikor a HTTP kérés befejeződött, az eseménysorba bekerül a hozzá tartozó esemény, amit az eseménykezelő ciklusunk nemsokára ki is vesz onnan, kikeresi a hozzá tartozó eseménykezelőt (a callback függvényünk), és meghívja azt.
The Pyramid of Doom
A koncepció remekül működik, megoldottuk a blokkolás problémáját. Helyette kaptunk egy másikat, ez a pyramid of doom. A probléma szemléltetésére nézzünk egy egyszerű NodeJS kódrészletet, amivel egy MongoDB adatbázison hajtunk végre egy lekérdezést:
connection.open(function (error, db) {
if (error) {
console.log(error);
return;
}
db.collection('user', function (error, collection) {
if (error) {
console.log(error);
return;
}
collection.find({age: {$gt: 18}}, function (error, cursor) {
if (error) {
console.log(error);
return;
}
cursor.toArray(function (error, array) {
if (error) {
console.log(error);
return;
}
array.forEach(function (user) {
console.log(user.name);
});
});
});
});
});A konkrét kód megértése nélkül is látszik, hogy valami nincs rendben. A probléma a nevét a fenti kódrészlet alakja miatt kapta. Még ha hozzá is szokik a szemünk az ilyen jellegű kódszervezéshez, semmiképpen sem egyszerű a megértése. Mi van akkor, ha az aszinkron függvény után futtatunk kódot, milyen sorrendben dolgozunk? A válasz természetesen itt most triviális, de ez nem jelenti azt, hogy minden esetben ilyen egyszerű kódunk van. Akár néhány elágazást beszúrva olyan komplexitású kódot kapunk, amit lehetetlen karbantartani.
Még számtalan probléma van ezzel a kóddal, de most koncentráljunk csak magára a piramis alakra (a többivel majd később foglalkozunk).
Lapítás
Első próbálkozásként megpróbáljuk kilapítani a piramisunkat:
connection.open(connectionOpened);
function connectionOpened(error, db) {
if (error) {
console.log(error);
return;
}
db.collection('user', collectionRetrieved);
}
function collectionRetrieved(error, collection) {
if (error) {
console.log(error);
return;
}
collection.find({age: {$gt: 18}}, cursorRetrieved);
}
function cursorRetrieved(error, cursor) {
if (error) {
console.log(error);
return;
}
cursor.toArray(resultsFetched);
}
function resultsFetched(error, array) {
if (error) {
console.log(error);
return;
}
array.forEach(printUser);
}
function printUser(user) {
if (error) {
console.log(error);
return;
}
console.log(user.name);
}A problémát nem oldottunk meg, csak elfedtük, ráadásul a sorrendiségnek is annyi (akár teljesen véletlenszerű sorrendben is felírhattuk volna a függvényeinket). A kód a goto spagetti szindróma jeleit mutatja. Debugoláskor ráadásul még a stacktrace sem nyújt semmilyen hasznos információt, hogy hogyan jutottunk el az adott függvénybe: emlékezzünk, itt az összes függvény (rendben, a forEach() kivétel) azonnal visszatér az eseményhurokba!
Hibakezelés
A másik probléma a hibák kezelése. A hibákat (amióta létezik kivételkezelés) throw-val (vagy ekvivalens nyelvi elemmel) dobjuk, majd valahol később azt egy catch blokkban kapjuk el. A callback alapú modellben ez nem működik, hiszen hiába tesszük például a connection.open() hívást egy try-catch blokkba, nem fogunk tudni elkapni hibákat, hiszen amikor az eredményt megkapjuk, a függvényünk már régen visszatért az eseményhurokba.
Támadhat persze az az ötletünk, hogy akkor adjunk át hibakezelő callback függvényeket is, de ezzel csak magunk alatt vágjuk a fát, hiszen bonyolítjuk az amúgy sem egyszerű kódunkat.
Vezérlési szerkezetek?!
A következő probléma, hogy viszonylag bonyolult ebben a modellben párhuzamosan, illetve sorosan (valamint ezek kombinációjában) műveleteket végezni. Természetesen felhasználhatjuk a már meglévő könyvtárakat (pl. Async) a problémáink orvoslására, de ezek leginkább csak tüneti kezelést nyújtanak.
Csak hogy valami fogalmunk legyen, írjuk meg a párhuzamos, illetve a soros végrehajtásra képes utility függvényeket. Párhuzamos végrehajtás alatt itt természetesen nem valódi párhuzamos végrehajtást kell érteni (egy szálon futunk!), hanem azt, hogy egymás után több aszinkron feladatot is elindítunk.
/**
* A megadott `job`-okat sorosan lefuttató függvény.
*
* Egy job egy függvény, aminek első paramétere egy callback függvény, amit
* akkor kell meghívni, ha végzett az aszinkron művelet.
* A függvénynek tetszőleges számú paraméter átadható, a következő job
* ezeket megkapja.
*
* @param jobs A feladatok tömbje
*/
function waterfall(jobs) {
var i = 0;
function next() {
i < jobs.length && jobs[i++].apply(null, [next].concat(Array.prototype.slice.call(arguments)));
}
next();
}Példa az egyszerű használatra:
// 3 mp alatt elszámol 3-ig
waterfall([
function (next) {
console.log(1);
setTimeout(next, 1000);
}, function (next) {
console.log(2);
setTimeout(next, 1000);
}, function (next) {
console.log(3);
setTimeout(next, 1000);
}
]);Nézzük meg ugyanezt párhuzamosan:
/**
* A megadott `job`-okat párhuzamosan lefuttató függvény
*
* A job egy függvény, aminek egy paramétere van, egy callback függvény,
* amit a job befejezésekor kell meghívni, maximum 1 paraméterrel.
* Ennek a paraméternek az értéke a job eredménye, a szinkronizációs
* pontban lefutó függvény ezt az értéket kapja meg.
*
* @param jobs A feladatok tömbje
* @param finish A szinkronizációs pontban (amikor minden job befejeződött)
* lefutó függvény.
*/
function parallel(jobs, finish) {
var results = [];
var remaining = jobs.length;
for (var i in jobs) {
jobs[i]((function (i) {
return function (result) {
results[i] = result;
if (!--remaining) {
finish(results);
}
}
})(i));
}
}Szintén egyszerű példakód a működésre:
// 1, 2, 3 azonnal, majd 3 mp után done!
parallel([
function (done) {
console.log(1);
setTimeout(done, 1000);
}, function (done) {
console.log(2);
setTimeout(done, 2000);
}, function (done) {
console.log(3);
setTimeout(done, 3000);
}
], function (results) {
// a results tömbben lenne a jobok eredménye, sorrendhelyesen
console.log('done!');
});Természetesen ezek csak egyszerű Móricka-implementációk, nem foglalkozunk a hibakezeléssel, esetleges timeout-okkal.
Promise
Használjuk a már meglévő eszközeinket az aszinkronitás problémáinak orvoslására! Az egyik lehetséges út a promise-ok használata. A promise egy olyan művelet eredményét reprezentálja, aminek az értéke a jelenben nem ismert. Az API azonban biztosít néhány eseményt (tipikusan success és error), amikre fel lehet iratkozni. Létezik egy ajánlás az interfészre, a Promises/A, ami tekinthető de facto, és létezik tucatnyi programkönyvtár (Q, node-promise, jQuery.Deferred stb.), ami többé-kevésbé implementálja ezt az interfészt.
Implementáljunk egy delay() függvényt, ami várakoztatja a futást, és a fentebb leírt tulajdonságokkal rendelkezik:
function delay(ms) {
var successHandler = null;
setTimeout(function () {
successHandler && successHandler();
}, ms);
var promise = {
then: function (f) {
successHandler = f;
}
};
return promise;
}Ezek után a meghívása valahogy így történhet:
delay(1000).then(function () {
console.log(1);
});Ez eddig nem tűnik túl érdekesnek, sőt, a hagyományos callback megoldásokhoz képest sem nyújt újat. A kód nem lett olvashatóbb, és a pyramid of doom sem tűnt el:
delay(1000).then(function () {
console.log(1);
delay(1000).then(function () {
console.log(2);
// és így tovább...
});
});A másik probléma, hogy minden aszinkron kódunkhoz (itt a delay()) hozzákötöttük a promise implementációnkat, válasszuk tehát külön a dolgokat.
Vezessük be a deferred objektum fogalmát. Ez egy aszinkron művelet reprezentációja, alapvetően két dolgot tud: sikeresen (resolve()), illetve sikertelenül végződni (reject()). Nem szeretnénk, ha ezt a két függvényt rajtunk kívül bárki meg tudná hívni, így a műveletet el kell választanunk az eredményétől (magára a műveletre nem kíváncsi a hívó fél, csak az eredményre). A Deferred-hez tartozik egy Promise objektum, a külvilág ezt kapja meg, ezen keresztül tud feliratkozni az eseményekre. Lássuk hát a kezdetleges implementációnkat:
var Promise = (function () {
function Promise() {}
Promise.prototype.then = function (success, error) {
this._success = success;
this._error = error;
}
return Promise;
}());
var Deferred = (function () {
function Deferred() {
this.promise = new Promise();
}
Deferred.prototype.resolve = function () {
this.promise._success && this.promise._success.apply(null, arguments);
};
Deferred.prototype.reject = function () {
this.promise._error && this.promise._error.apply(null, arguments);
}
return Deferred;
}());Írjuk át a delay() függvényünket, hogy az új API-t használja:
function delay(ms) {
var defer = new Deferred();
// A `bind`-re csak azért van szükség, hogy a `this`
// helyes értéket kapjon a `resolve` függvényben
setTimeout(defer.resolve.bind(defer), ms);
return defer.promise;
}Készen van a minimálimplementációnk, viszont a piramisunk ugyanúgy megvan. A promise minta attól lesz igazán hatékony eszköz a kezünkben, hogy láncolható. Azaz a then() függvény szintén egy Promise objektumot ad vissza, ami akkor lövi el a success eseményét, ha a then() függvényben átadott függvény eredménye is ismert, azaz ha az is egy Promise-t ad vissza, akkor annak a feloldásakor. Lássuk tehát az okos(abb) Promise implementációnkat:
var Promise = (function () {
function Promise() {
// jobb híján elhisszük, hogy akinek az isPromise attribútuma igazra
// értékelődik ki, az egy Promise...
this.isPromise = true;
}
Promise.prototype.then = function (success, error) {
var defer = new Deferred();
this._success = function () {
var r = success.apply(null, arguments);
if (r && r.isPromise) {
r.then(defer.resolve.bind(defer), defer.reject.bind(defer));
}
}
this._error = function () {
var r = error.apply(null, arguments);
if (r && r.isPromise) {
r.then(defer.resolve.bind(defer), defer.reject.bind(defer));
}
}
return defer.promise;
}
return Promise;
}());A műveleteink így már láncolhatóak:
delay(1000).then(function () {
console.log(1);
return delay(1000);
}).then(function() {
console.log(2);
return delay(1000);
});Eltűnt a piramis, a végrehajtás szekvenciális. Még egy dolog maradt hátra, a hibakezelés. Szeretnénk, ha a throw-val eldobott hibákat el tudnánk kapni, és a try-catch blokkokhoz hasonlóan a hibát nem feltétlenül a keletkezés helyén szeretnénk kezelni. Ehhez manuálisan kell megvalósítani a kivételek eljuttatását a megfelelő helyre. Nézzük meg tehát a végső Promise implementációnkat:
var Promise = (function () {
function Promise() {
this.isPromise = true;
}
Promise.prototype.then = function (success, error) {
var defer = new Deferred();
function makeFunction(f) {
return function () {
try
var r = f.apply(null, arguments);
if(r && r.isPromise) {
r.then(defer.resolve.bind(defer), defer.reject.bind(defer));
} else {
defer.resolve(r);
}
} catch (e) {
defer.reject(e);
}
}
}
this._success = typeof success === 'function' ? makeFunction(success) : defer.resolve.bind(defer);
this._error = typeof error === 'function' ? makeFunction(error) : defer.reject.bind(defer);
return defer.promise;
}
return Promise;
}());A kipróbáláshoz vegyük elő ismét az adatbázisos példánkat. A példában egy szimulált adatbázishoz fogunk csatlakozni (setTimeout()-ok alkalmazása, szimulált hibák), és az eredeti API a hagyományos callback alapú lesz, (error, result) szignatúrájú callback függvényekkel (utolsó paraméterként).
var connection = function () {
var connection = {
open: function (f) {
setTimeout(function () {
if (Math.random() > 0.9) {
f('Hiba az adatbázishoz csatlakozás közben!');
} else {
f(null, db);
}
}, 1000);
}
};
var db = {
collection: function (name, f) {
setTimeout(function () {
if (Math.random() > 0.8) {
f('Hiba a `' + name + '` kollekció lekérése közben!');
} else {
f(null, coll);
}
}, 1000);
}
};
var collection = {
find: function (condition, f) {
setTimeout(function () {
if (Math.random() > 0.7) {
f('Hiba a lekérdezés közben a `' + JSON.stringify(condition) + '` feltétel mellett!');
} else {
f(null, cursor);
}
}, 1000);
}
};
var cursor = {
toArray: function (f) {
setTimeout(function () {
if (Math.random() > 0.6) {
f('Hiba az eredmény tömbbé konvertálása közben!');
} else {
f(null, array);
}
}, 1000);
}
};
var array = [{name: 'Sándor'}, {name: 'József'}, {name: 'Benedek'}];
return connection;
}();Írjuk meg a függvényt, ami tetszőleges callback alapú API-ból képes Promise-t gyártani!
function promisify (f) {
return function () {
var defer = new Deferred();
var args = Array.prototype.slice.call(arguments, 0);
f.apply(null, args.concat([function (error, resolution) {
if (error) {
defer.reject(error);
} else {
defer.resolve(resolution);
}
}]));
return defer.promise;
}
}Végül pedig használjuk az elkészült API-t a promisify() függvénnyel kombinálva. Természetesen szerencsésebb lenne, ha az API köré egy wrapper objektumot írnánk, de a célnak ez is megfelel.
console.log('Csatlakozás...');
promisify(connection.open)().then(function (db) {
console.log('A `user` kollekció lekérése...');
return promisify(db.collection)('user');
}).then(function (collection) {
if(Math.random() > 0.7) {
throw new Error('Húha, én mégsem ezt akartam!');
}
console.log('Keresés...');
return promisify(collection.find)({age: {$gt: 18}});
}).then(function(cursor) {
console.log('Találatok tömbbé konvertálása...');
return promisify(cursor.toArray)();
}).then(function (array) {
array.forEach(function (user) {
console.log('Név: ' + user.name);
});
}, function (error) {
console.log('Hiba: ' + error);
});Vegyük sorra a régi problémákat, és nézzük meg, találtunk-e rá megoldást:
- Az átláthatatlan, egymásba ágyazott callback függvényeket megszüntettük.
- A sorrendiség adott, ha akarunk sem tudunk suttyomban rossz sorrendben kódot végrehajtani.
- A hibakezelés egységes és egyszerű,
throwhasználható.
Coroutines
Az aszinkronitás problémájára megoldást nyújt a (koránt sem újkeletű) coroutine-ok használata, illetve valójában kistestvéreik, a generátorok az a koncepció, ami jelenleg bontogatja a szárnyait JavaScript környezetben.
Mit jelent ez számunkra? Vegyük a szinkron hello world webszolgáltatásos példánkat újra elő:
button.onclick = function () {
// az `await` kulcsszót C#-ból köcsönöztem
var result = await betterAJAX.get('/hello?name=' + name);
resultBox.innerHTML = result;
}Coroutine-ok használatával a fenti kódrészlet futása így zajlik le (sajnos szekvenciadiagramon ez nem túl szemléletes):
- Meghívódik az
onclickfüggvényünk - Meghívódik a
betterAJAXfüggvényünk - Az
onclickvisszatér - Az eseménykezelő ciklus reagál az eseményekre
- Ha megjött a HTTP válasz, a hozzá tartozó esemény bekerül az eseménysorba
- Az
onclickfüggvényünk folytatja a futását (aresultváltozóba bekerül az eredmény) - Az eredmény megjelenik a megfelelő DOM elemben, majd visszatér a függvény
De hogyan is lehetséges ez a fajta működés? Közelítsük meg a problémát az értelmező (interpreter) oldaláról. A JavaScript, hasonlóan sok más programozási nyelvhez, egy darab stack-kel rendelkezik. Ez viszont ilyen esetekben nem lesz elég: hisz az onclick-ben rendelkezünk egy stack-kel, majd (miközben várunk az eredményre) az eseménykezelő hurok más függvényhívásokat is indít, amik saját stack-kel rendelkeznek. Az eredmény megérkezése után helyre kell állítanunk a futás állapotát, ezt a stack segítségével tudjuk megtenni, ez tehát nem veszhet el. Látszik, hogy ezeknek a problémáknak a megoldása nem egyszerű, az értelmezőt fel kell készíteni (stack elmentése, betöltése, illetve az eredmény szempontjából lényegtelen, hogy hogyan oldja meg), illetve ennek megfelelően az ECMAScript szabványt is bővíteni kell új kulcsszavakkal (az ECMAScript jelenleg kidolgozás alatt álló 6-os verziója tartalmazza a specifikációt).
A másik lehetőség, ha egy plusz réteget iktatunk be az interpreter és a saját kódunk közé: egy fordítót (compiler), ami át tudja alakítani a kódunkat, hogy az a JavaScript jelenlegi verziója számára is emészthető maradjon, nekünk viszont biztosítsa a kényelmet. Természetesen ha egy komplett fordítót vonunk be a képbe, akkor egyáltalán nem kötelező a JavaScript szintaktikájánál maradnunk. A fordítókra talán a legjobb példa a CoffeeScript, illetve az IcedCoffeeScript, ami a korutinokhoz hasonló funkcionalitást támogat, de számtalan egyéb megoldás is létezik (Kaffeine, tamejs stb.). Ha a hagyományos JS szintaktikával szimpatizálunk, akkor is vannak eszközök (traceur, Mascara stb.), ami ES6 lehetőségeket használó JS kódot fordít ES5 szabványos kódra. A fordító az átalakítást (nagy vonalakban) úgy végzi, hogy felbontja a függvényünket az ilyen „szakadások” mentén, és egy nagy switch-be ágyazza, így amíg mi egyetlen függvényt látunk, aminek gyakorlatilag tetszőleges pontjára be tudunk lépni, az valójában sok kicsi, és a switch segítségével tudunk a megfelelő helyre ugrani (és persze a belső állapot tárolása is meg van oldva).
A korutinok/generátorok jelenleg nem túl elterjedtek, mivel a böngészők közül csak a Firefox implementálja (és ez az implementáció sem szabványos). Szerveroldalon a fibers nyújt ilyen jellegű funkcionalitást.
Generátorok
Barátkozzunk össze a yield kulcsszóval. Ha függvénybe tesszük (márpedig oda tesszük, hiszen máshol elhelyezve hibát kapunk), akkor az a függvény generátor (más néven iterátor, igaziból ez szemantika kérdése) lesz. Mi is az a generátor? Vegyük például a négyzetszámokat. Írjunk egy generátort, amivel elő tudjuk állítani az összes négyzetszámot:
function squares() {
var i = 1;
while (true) {
yield i * i;
i++;
}
}Vegyük használatba:
var s = squares();
for (var i = 0; i < 10; i++) {
console.log(s.next());
}A next() függvény hatására a generátorunk elkezd futni, majd a yield kulcsszónál található értékkel visszatér (most fogjuk föl úgy, mint egy return), viszont a következő next() hívásnál ugyaninnen folytatja a futását. Nekünk pont ez a funkcionalitás kell, használjuk hát ki.
Alkalmazás
Implementáljunk egy egyszerű AJAX-os hívást korutinok segítségével. Valójában ez generátor/iterátor, de a két fogalom szemantikai szempontból nem igazán jó elnevezés, szóval maradok a korutinoknál (hiszen a generátorok a korutinok részhalmaza). A használathoz a kódokat Firefoxban kell futtatni, egy type="application/javascript;version=1.7" attribútummal ellátott script blokkban:
job(function () {
console.log('waiting...');
var result = yield fakeAjax('/hello?name=weblabor');
console.log(result);
});Egy ilyen jellegű kódrészletet szeretnénk működésre bírni (a fakeAjax() trükkös jószág, egyszerűen egy setTimeout()-os késleltetéssel adja vissza az eredményt). Mi is történik itt? A yield fakeAjax() visszatér a függvényből a fakeAjax() visszatérési értékével. Ez a visszatérési érték egy függvény, ami egy paramétert vár, egy callback függvényt, amit akkor hív meg, amikor végzett az aszinkron művelettel.
function fakeAjax(url) {
return function (done) {
setTimeout(function () {
done('Hello ' + url.substr(url.indexOf('?name=') + 6) + '!');
}, 2000);
}
}Már csak egy olyan mechanizmust kell megírnunk, ami visszaadja a vezérlést az aszinkron művelet végén a függvényünknek, ez lesz a (varázslást végző) job() függvény.
function job(f) {
var job = f();
(function next(result) {
try {
var waitfor = job.send(result);
waitfor(function (result) {
next(result);
});
} catch (e) {
// Ha a `job` végén nincs return, egy StopIterationExceptiont kapunk...
if (!(e instanceof StopIteration)) throw e;
}
}());
}A job() egy generátort (egy olyan függvényt, amiben van yield) vár, első lépésként példányosítja a generátort. Ez szintaktikailag megegyezik a függvény végrehajtásával, viszont fontos megjegyezni, hogy ekkor a függvény törzse nem értékelődik ki.
Ezek után a generátor send() függvényével elkezdi a futtatást – paramétere az előző (ha van) yield eredménye – és elkéri a következő értékét a generátornak. A kapott (függvényt) végrehajtja, átadva neki azt a callback függvényt, ami a következő aszinkron műveletet végrehajtja. A try-catch blokk azért kell, hogy ne kapjunk hibát az utolsó aszinkron művelet után (mivel utána nincs több yield, tehát a generátornak nincs következő értéke).
Coroutine + Promise = Task?
Végezetül próbáljuk meg a két módszert kombinálni! A promise minta rendkívül jó absztrakciót nyújtott az aszinkron műveleteink különbözőségeire, a korutinok pedig a szintaktikai bonyolultságot fedték el hatékonyan.
Módosítsuk a job() függvényünket, hogy az a Promise API-t használja:
function job(f) {
var job = f();
(function next(result) {
try {
var waitfor = job.send(result);
(function usePromise(waitfor) {
waitfor.then(function (result) {
next(result);
}, function (error) {
usePromise(job.throw(error));
});
})(waitfor);
} catch (e) {
if (!(e instanceof StopIteration)) {
console.log('Hoppá, el nem kapott kivétel!');
console.log(e);
}
}
}());
}Érdekesség, hogy a Promise sikertelensége (error esemény) esetén hibát tudunk dobni, amit a hagyományos (try-catch) szintaktikával tudunk elkapni/feldolgozni.
Végül a teszt:
job(function () {
try {
console.log('Csatlakozás...');
var db = yield promisify(connection.open)();
console.log('A `user` gyűjtemény lekérése...');
var collection = yield promisify(db.collection)('user');
console.log('Keresés...');
var cursor = yield promisify(collection.find)({age: {$gt: 18}});
console.log('Találatok tömbbé konvertálása...');
var array = yield promisify(cursor.toArray)();
array.forEach(function (user) {
console.log('Név: ' + user.name);
});
} catch (e) {
console.log('Ajjajj, nagy a baj: ' + e);
}
});Az igazán szép persze az lenne, ha a job() is egy Promise-t adna vissza, ami természetesen nem elkapott kivétel esetén reject-et kap, a job végén pedig resolved-ot.
A Promise és korutinok kombinációját használja a task.js könyvtár, ami fenti naiv megoldásoknál sokkal robusztusabb, és több programozási lehetőséget biztosít.
Konklúzió
JavaScriptben számos lehetőségünk van, ha aszinkron módon szeretnénk programozni, ehhez rengeteg eszköz áll rendelkezésünkre, de egyik sem silver bullet, mindnek megvan a maga helye. Munkánk során mindig mérjük fel a lehetőségeinket, és ennek megfelelően válasszuk ki a használni kívánt megoldást. Viszont fontos, hogy ne csak használjuk, hanem értsük is a mögöttük húzódó koncepciókat, hiszen csak így tudunk objektívan dönteni, a feladathoz az optimális megoldást megtalálni.
Maga az aszinkron programozás rendkívül pezsgő terület, a közeljövőben várhatóan egyre több megoldás fog születni ezen a téren, én személy szerint bízok benne, hogy a böngészőkben (de természetesen szerver oldalon is) hamarosan el fog terjedni a korutinok használatának lehetősége.
A bélyegképen Paola fényképe látható.
■



Aszinkronitás
Korábban már volt valamelyik blogmarkban vita erről, és ott is felvetettem ezt a gondolatot: hordoz-e információt az adott kontextusban az, hogy egy kérést aszinkron indítok el? Azon kívül, hogy elmondhatom: na, ez aszinkron történik, nem igazán, hisz csak az számít, hogy mit kapok vissza eredményül. Szóval szerintem az aszinkronitást nyugodtan elrejthetnék előlünk a futtatókörnyezetek.
Érdekesség: nemrég kiderült, hogy a legújabb Firefox egy fül bezárásakor az onunload eseményben kiküldött AJAX-hívást egyszerűen nem futtatja le (fél éve még nem csinált ebből problémát). Némi keresgélés után kiderült, hogy ilyenkor kivételesen szinkron módon kell kérni.
Némi keresgélés után
Ilyenkor késik a fül bezárása is?
Nem tudom
hordoz-e információt az adott
Az elrejtés nem feltétlenül jó, sőt. Többek között ezért utálja mindenki a többszálú programozást:
fooaszinkron, csak a futtatókörnyezet "elrejti" ezt. Annyit tudunk róla, hogy aziértékéhez hozzá sem nyúl, nem is hallott róla.A kód havonta egyszer 4-et ír ki, ami miatt minden alkalommal háromcsillió pengő bevételkiesése van a cégnek. Sok sikert a debugoláshoz :)
Például a php-nak minden
van "aszinkron php" :)
Igen, a PHP-ban minden szinkron, azaz ha egy socketen nem jön adat, te pedig freadet (ami pl unix rendszereken valószínűleg egy read rendszerhívás lesz) küldesz rá, akkor a php futtatókörnyezete nem fog (nem tud) más php kódot futtatni. Nodejs esetében ez a rendszerhívás nem történik meg (azonnal), helyette az eseményhurok futtat egy select-et (a pontos megvalósítást nem ismerem, és nem is különösebben érdekel), tehát csak akkor történik olvasás, ha már van mit.
nem teljesen értem, hogy jön
Úgy értettem, hogy az
Nem értem
Teljesen másak a felhasználói felületen bekövetkezett események, például egy billentyűleütés vagy egérkattintás, ott már lényeges az időfaktor is.
Miért nem hasonlítanak?A cikk
Ha arra célzol, hogy AJAX
Pont azért tehető meg a
Nem értem
Ne haragudj, nem kekeckedni akarok veled, de tényleg meg szeretném érteni, hogy egy darab projekt havonta egyszer előforduló hibája miatt miért kéne egy olyan programozási módszert/szintaktikát alkalmazni, amiről az első percben kiderül, hogy nehézkes (callback hell), és különböző új szintaktikai elemeket és módszereket kell bevezetni, hogy hatékonyan lehessen dolgozni vele. Ennyi erővel egyébként minden függvényt aszinkron módon kéne meghívni a debugolási veszélyek miatt, nem?
A különbség egyszerű
Nem erre gondolok.Most
Most hogyan működik egy AJAX kérés?
var xmlhttp = new XMLHttpRequest();
xmlhttp.onreadystatechange=function() {
if (xmlhttp.readyState==4 && xmlhttp.status==200) {
document.getElementById('div').innerHTML = xmlhttp.responseText;
}
};
xmlhttp.open('POST', 'ajax_info.txt', true);
xmlhttp.send();
}
Mint látható, a kód teljesen fragmentált. Egyik helyen indítom, másik helyen fejezem be, ráadásul az esetleges korábban definiált változók - megoldástól függően - nem feltétlenül érhetők el. Az AJAX kérés kódját tehettem volna külön függvénybe, de a lényeg, hogy a visszakapott adatokat mindenképp másik függvényben tudom feldolgozni.
Mi lenne szerintem ideális? Tegyük fel, létezik egy Request nevű beépített objektum a javascriptben.
Ajax_Keres.async = true;
gomb.onclick = function gomb_klikk() {
var keres = Ajax_Keres.request({url: 'ajax_info.txt'});
if (!keres.error) {
document.getElementById('div').innerHTML = keres.responseText;
}
}
A kontextus a gomb onclick eseménye, a feladat, hogy a kérésre érkezett választ rakjam be egy divbe. Ehhez ebben az esetben nem kell kilépnem a kontextusból, és máshonnan folytatni a feldolgozást, az esetlegesen definiált helyi változók is megmaradnak. Ez átláthatóbb és karbantarthatóbb kódot eredményez, és nincs szükség új szintaktika bevezetésére. A futtatókörnyezet foglalkozik az aszinkron kérés problémáival, előlem elrejti ezt, mert ebben a kontextusban nem érdekel, miként oldja meg. A kérés alatt természetesen kattintgathatok, gépelhetek, ami csak jólesik.
Ez azért nem oldható meg,
Megoldható
XMLHttpRequestobjektumnakonreadystatechangeeseményvezérlőt, és abban folyamatosan értesülhetsz a változásokról, azaz az általad említett debugolás is ugyanúgy megoldható, mint eddig. Innentől kezdve logikailag pontosan ugyanott vagy, mint AJAX kérés esetén, csak nem esik szét a kód.Valószínűleg nagyjából úgy működik, hogy az eseménysor (queue) vezérlését megkapja és zárolja az
XMLHttpRequestobjektum, de attól függetlenül ő persze adhat hozzá új elemeket. Innentől kezdve egy paraméter kéne a kiegészítéshez, hogy az AJAX kérést is ugyanezzel a szintaktikával futtassa. És ha itt működik, átvehetné a dolgot mondjuk a node.js és a többi hasonszőrű nyelv, és (majdnem) az egész aszinkron programozásról el is felejtkezhetnénk. Jó a cikked, nagyon szépen összeszedett, de olyan problémára keres megoldást, aminek – kis túlzással – nem kéne léteznie. A böngészőkonclickeseményéhez hasonlóak persze megmaradnának, de programlogikailag általában ez a legkevesebb.Az ajax "soros" kéréseknél
Milyen párhuzamos kérésekre
Mondjuk az említett gombra
A nodejs-ben azért van szükség aszinkron kérésekre, mert a program, amit írsz nem egyetlen felhasználó egyetlen kérését szolgálja ki, így muszáj párhuzamosítani ahhoz, hogy egy kérés ne blokkolja le az összes többit. Körülbelül olyan, mint egy php daemon, amit több felhasználó is hívhat egyszerre. Gondolom ott is problémákat okoz a párhuzamos kérések feldolgozása...
Ha egy szerverről kell
Az a helyzet, hogy pont hogy
A gombos példánál maradva végülis hasonlóan piszkos:
Egyáltalán nem igaz, hogy
És nem azt akarom mondani, hogy az SJAX az annyira jó és az AJAX (és az aszinkron programozás) rossz. Az utóbbinál a szintaktika miatt a kód szétesik, kevésbé lesz átlátható, és közben nem is nyerünk vele semmit. Hát ezért lenne jobb, ha a futtatókörnyezetek ezt elrejtenék előlünk, és tudnánk olyat csinálni, hogy
var result = AJAX.get('/hello?name=' + name);.A példáddal kapcsolatban: ránézésre melyik mód az átláthatóbb és könnyebben karbantartható?
Azt hiszem ez elég
Ez a probléma szerintem inkább abból fakad, hogy a js eleve szinkron megoldásokra lett kitalálva, nincsenek olyan nyelvi elemek benne, amik az aszinkron kódolást könnyebbé tennék. Most már van a yield 1.7-es verziótól, és ha megnézed a cikket, akkor a yield-es példa néz ki a legjobban... Esetleg ha még betesznek több ilyen nyelvi elemet, ami aszinkron kéréseknél segít, akkor kódolás szempontjából nem lesz nagy különbség a két változat között... Nem feltétlenül kell ezeknek ugyanúgy kinéznie, mint a szinkron kéréseknek, mivel nem azok, de lehetnek hasonlóan egyszerűek... A többletinformáció, amit hordoznak, hogy az utánuk jövő sorban lévő kód időben nem feltétlenül utánuk fog lefutni. Ezt nyelvi elemekkel javítani lehet. Szóval végülis igazad van abban, hogy jó lenne, ha fejlesztenék a nyelvet ilyen téren, abban viszont szerintem nincs, hogy el kellene rejteni azt, hogy egy kérés aszinkron, vagy szinkron.
A többletinformáció, amit
1, adott egy gomb,
2, ha rákattintanak, akkor indítson kérést,
3, majd, ha megjött a válasz, frissítse a három doboz tartalmát.
var result = AJAX.get('valami.php');
if (!result) {
return 'Nincs adat';
}
box1.innerHTML = result.box1;
box2.innerHTML = result.box2;
box3.innerHTML = result.box3;
};
Számodra, az oldal fejlesztője számára milyen többletinformációt jelent, hogy tudod: a kérés egy AJAX kérés?
Mi a különbség a fenti példa között, és aközött, hogy a 2-es pontban nem kérést indít, hanem egy, már a memóriában lévő tömb tartalmát kérdezed le egy függvénnyel, ami ugyanolyan formában adja vissza a választ, amit a 3-as pontban lévő függvénnyel dolgozol fel, és frissíted a három doboz tartalmát?
var result = lokális_tömb_csócsál(adatok_tömbje);
if (!result) {
return 'Nincs adat';
}
box1.innerHTML = result.box1;
box2.innerHTML = result.box2;
box3.innerHTML = result.box3;
};
Én úgy látom, hogy nincs különbség az adott kontextusban (az onclick függvényben). Teljesen érdektelen számomra, honnan és miként kapom az adatokat. Egy dolog fontos, hogy ha nem érkezik adat meghatározott időn belül, akkor hibaüzenetet kell megjelenítenem, de ez a kontextus szempontjából érdektelen (mindkét esetben ki kell lépnem belőle).
A példád nem jó, mert csak
Ok, így már értem. A magam
Tudnál példát írni arra, hogy
Egy stack és a Firefox
Ebből következne az, hogy amíg szinkron lekérésre várok, más nem történhet, Firefox esetén azonban belefutottam egy hibába, miszerint blokkolt futás (szinkron lekérés, modális popup, stb.) közben kiváltódhat más esemény, szerintük:
Szerencsére ez csak Firefoxnál van így.
Nagyon jó a cikk, külön örülök, hogy a generátorokra is kitértél.
Nem tudom, hogy a FF belseje
Amit javasolsz, azt lehet
Nem teljesen értelek, a
Egyrészt AJAX hívásról volt
Másrészt a példádban szereplő
"syncSleep(5000); //mert ez bizony blokkol"
félrevezető, mert csak részben igaz, ugyanis VALÓBAN blokkolja a javascript motort, de NEM blokkolja a böngésző eseménykezelőit, azaz ha a egy gombra klikkelés indítja a hívást, akkor jön az igazi torkosborz, mert 20 kattintás 20*5 másodpercre fagyasztja a böngészőt (mindent). Gratulálok a "megoldásodhoz".
Egyébként a Firefox bughoz én annyit fűznék hozzá, hogy alapvetően igaza van mindenkinek.. tényleg bug-nak tűnik, de a fickó se irt hülyeséget. A probléma inkább ott van, hogy miért használ valaki (2011-ben) sync-es hívást? Vagy ha használ miért bízza a böngészőre a "lockolást"? Ezekre csak rossz válasz adható.
Egyébként, ha már..
.. tetszik a cikked, egy problémám van vele, hogy a végeredmény, amit kihoztál belőle a végén is szörnyű. A legnagyobb probléma vele, hogy teljesen átláthatatlan, fejleszthetetlen az egész. Tökéletes arra, ha egy cégnél olyan kódot akarsz írni, amit rajtad kívül senki nem "ért", csak pár óra "forráskód" böngészés után és kvázi "kirúghatatlan" leszel tőle.
Tipikus javascriptes agymenés, amivel tele van a net, holott az adott problémákra évtizedek óta van tisztább, szárazabb érzésű megoldás, ami javascriptben is működik.
Ácsi
Elnézést kérek, igazad van.
Természetesen javascripttel
Ha példakódok ha nem világosak, szívesen elmagyarázom őket :), a cikk elején direkt ezzel kezdtem: "többnyire nem teljesek, nem optimálisak,", azaz a lényeg az, hogy működik egy felvázolt részprobléma megoldására, senkinek sem ajánlom, hogy álljon neki saját implementációkat hegeszteni...
Én nyitott vagyok az újdonságokra, szóval szívesen hallanék más megoldásokról is.
A hozzászólásod első
max. egy Hello world-ben használható, de a fenti AJAX-os probléma megoldására semmiképp.
Ami a cikket illeti és a más megoldást illeti.
Az adott (konkrét) problémára ami a "The Pyramid of Doom"-nál kezdődik,
egy objektum alapú megközelítés és megoldás az "igazi", az amit leírtál semmiképp
( az okokat már az előző hozzászólásomban leírtam), mint ahogy "Promises" megoldása (lentebb) is sokkal átláthatóbb vele.. még ha az túl általános is.
A Tied is nyilván működhet, csak "kicsit" bonyolultabban és "kicsit" rossz működő megoldást mutatva, mivel ennél egyszerűbben is lehet javascriptben jobban és szebben programozni.
Most tulajdonképpen melyik
Egy ilyesmi megoldás (a
Conn.prototype =
{
open: function()
{
this.state = "OPEN";
database.open( this.process );
},
process: function( error, object )
{
if ( error )
console.log( error );
switch ( this.state )
{
"OPEN":
this.STATE = "COLLECTION";
object.collection('user', this.process );
break;
"COLLECTION":
this.STATE = "FIND";
object.find({age: {$gt: 18}}, this.process );
break;
"FIND":
this.STATE = "TO_ARRAY";
object.toArray( this.process );
"TO_ARRAY":
this.state = "END";
object.forEach(function (user) {
console.log(user.name);
});
}
}
}
(conn = new Conn()).open();
Persze ez csak egy modell, sok hibája van, többek közt a "this".
Ennek egy működő változatát letesztelten node.js/postgres alatt,
de mivel nem ismerem és nem is akarom megismerni a node.js-t így
nem igazán izgat, szinte biztos meg lehet oldani.
A lényeg, hogy áttekinthető és jól fejleszthető, mint úgy általában
az OOP megoldások.
:-)
switchszerkezetemet, nekem ez túl nagy overhead. Plusz ez (lényegében) ugyanaz mint awaterfall, csak kicsit hosszabb...Bocs, de több dologban
Egyrészt a waterfall szintén a semmire sem jó kategóriába tartozik,
mert egy adott feladatra alkalmas, azontúl viszont használhatatlan a kód, főleg ott, ahol hibakezelést és több "szempontot" is fegyelembe kell venni. Szóval valós körülmények között nagyon-nagyon korlátozott a használata.
A másik, hogy a switch szerkezetet, csak egyszer kell megírni, mivel js-ben is van öröklődés, ezért a nagy overhead nem állja meg a helyét, max. a Te megoldásodnál, ahol valóban nagy overhead ugyanazt a kódot 100x leírni, egy komolyabb alkalmazásnál.
Harmadrész az adott model, egy kis fejlesztéssel korrektebbül megoldja a "Promise" problematikát.
Részemről én mindent elmondtam.
Örökléssel nem fogod a switch
Az én
waterfallmegvalósításomnál csak az egyes lépéseket megvalósító függvényeket kell megírni, ezt szerintem nem lehet kihagyni. (persze ha tudsz egy jó módszert, amivel a gép kitalálja helyettem, hogy mit akarok csinálni, szívesen meghallgatom)Ahogy a cikkben is leírtam, az ilyen végtelenül egyszerű szituációkban teljesen korrekt megoldás az ilyen egyszerű aszinkron vezérlési szerkezetek alkalmazása, ha ennél több kell, akkor ott a Promise és többi lehetőség.
Tényleg utolsó hozzászólás a
Egy szóval sem említettem, hogy a switch-et lehet módosítani öröklődéssel és ne vedd zokon, de el kellene kezdened komolyabb nyelvekkel (C változatok, Java, stb..) is foglalkoznod mint a Javascript és nem csak ismerkedési szintig, ugyanis látszik a hozzászólásodból, hogy a béka segge alatt van OOP a téren a gyakorlati ismereted, tapasztalatod. De nincs ezzel baj, mindenki volt ezen a szinten, viszont ez az oka annak, hogy mi addig nem fogunk egyetérteni, és hogy nem érdemes rámutatnom az utolsó hozzászólásodban lévő "csacskaságokra".
A Promise meg szintén egy "végtelenül egyszerű szituációkban teljesen korrekt megoldás", nem szabad túlértékelni, csupán egy logikai model, minimális gyakorlati haszonnal.
Nem tudom még hogy alakul, de ha lesz időm a nyáron megírom a cikked 2.0-as változatát.
ha lesz időm a nyáron megírom
Írtál egy példakódot, melyről
A publikált kódoddal nekem továbbra is az a problémám, hogy:
Használjunk állapotgépet ott, ahol állapotgépre van szükség. Egy ilyen lineáris műveletsorozatnál nincs erre szükség.
A véleményemmel, miszerint (többek között) a waterfall "egyszerű szituációkban teljesen korrekt megoldás", nem vagyok egyedül, elég csak megnézni, hogy az async a második leggyakoribb nodejs package dependencia.
Most ahhoz nem is szólnék hozzá, hogy a hozzászólásaimból és JavaScript példakódjaimból milyen következtetéseket tudsz leszűrni Java/C++/stb kódjaimra vonatkozóan :), ráadásul milyen hangnemben.
switch
Kellemesebb :). Viszont a kód
Működés
Abban mindenképp igazad van,
mert rossz, mint ahogy az ajax-os példa is az, mivel mind a kettő sokkal bonyolultabb story, és a promise és egyéb megoldások alkalmatlanok a megoldásukra.
Az adatbázisos példa abból a szempontból jó, hogy meg is lehet valósítani.
A problémám, amiért nem tudom Neked előhúzni a nyuszit a kalapból, hogy nem ismerem a node.js-t és már elkezdtem olvasgatni, mindig az egyik post jut az eszembe, aminek a lényege: "that shit works".
Idáig jutottam Postgres db-vel (működő kód):
hello_include.js
conString = "tcp://{USERNAME}:{PASSWORD}@localhost/{DATABASE}";
TConnection = function(){};
TConnection.prototype =
{
open: function( )
{
this.state = 0; // Not connected
this.client = new pg.Client( conString );
this.client.connect( this.callback( this ) );
},
close: function()
{
this.client.end();
this.client = null;
},
process: function( error, result )
{
if ( error )
{
this.error();
}
else
{
switch ( this.state )
{
case 0: // Not connected
this.state = 1; // Connected
this.query();
break;
case 1:// Process query response
this.state = 1; // Query ok
this.response( result )
}
}
},
callback: function( _this_ )
{
return function( a, b )
{
_this_.process.call( _this_, a, b );
_this_ = null;
}
}
};
hello.js
getInstance = function ( superName, protoFunctions )
{
var a = function(){}
a.prototype = new superName();
for ( fn in protoFunctions )
a.prototype[fn] = protoFunctions[fn];
return new a();
};
//app.get('/', function( request, response )
//{
getInstance( TConnection,
{
query: function()
{
this.client.query('SELECT NOW() AS "theTime"', this.callback( this ) );
},
response: function( result )
{
console.log( result.rows[0].theTime );
this.close();
},
error: function( error )
{
console.log( error );
// Hibakezeles ..
},
timeout: function()
{
// Timeout
}
}).open( "request", "response" );
//});
Ebben a megvalósításban
a) nincs piramis szerkezet
b) 2-4 egymástól jól elszeparált függvényt kell csak megírni: a lényeget
c) fejleszthető, mert a fejlesztést elég szinte csak az inculde-t "osztályban"
elvégezni.
Ellenben biztos, hogy nem a legjobb, mert ahhoz sokkal több időt kellene a node.js megismerésével eltölteni, azaz lehet, hogy blokkol valahol, lehet bukik az egész valamely a node.js tulajdonság miatt, stb., viszont működik.
Ha nem tetszik az open(), nevezd át nyugodtan szörözésre()
A probléma inkább ott van,
Így kellett volna írnod:
Amennyiben valaki olyan webes alkalmazást akar írni,
ahol más esemény nem történhet meg, azt szerver oldalon kell megoldania és csakis ott,
mert a kliens oldalt nem lehet teljesen "megbízhatóvá" tenni.
Nem csakis
[off]
Egyébként még mindig nem sikerült nem tulok módon megfogalmaznod, amit akartál mondani, bár nem is látszik túlságosan az igyekezet.
[/off]
Tény, hogy kliens oldalon is
Szóval, ha hiszel a tündérmesékben és abban, hogy a kliens oldal megbízható, akkor kliens oldali megoldást alkalmazol.
Senki sem mondta, hogy az
Olvasd el az első mondatát
Te is, és lehetőleg a
.. tetszik a cikked, egy
Tipikus javascriptes agymenés, amivel tele van a net
Funkcionálhat egyfajta
Köszi a fibers-ért, ezt nem
Promises
Blokkolás
A szinkron hívás hátránya az,
Egyedül mobilneten tudok
Attól függetlenül, hogy ez a
milyen gyakorlati esetekben használhatóak a fentiek?
0) Azt nem értem, hogyha valami váratlan hibára fut mondjuk egy DB lekérdezést futtató esemény, akkor miért jó az, ha a kódunk tovább fut (legalábbis az egymásra épülő részek esetében)
Vagy ez a probléma nem egy adott modellt érint (pl db lekérdezés+kiíratás) hanem minden mást is (a teljes alkalmazást?) Pl a "lekérdezés eredményét megjelenítő popuplayer "bezáró" gombjának eseménykezelőjét is?
1) Milyen esetben jó és rossz ez a megoldás? (1-2 gyakorlati példa?)
Azért is kérdezem, mert a hozzászólások elég ellentmondásosak, elbizonytalanítottak (ráadásul tele vannak személyeskedéssel)
Próbáld ki ezt debug-ra:
Ez egyáltalán nem igaz, bármelyik aszinkron sequence megoldást használod, mindegyiknél az van, hogy hiba esetén nem küldi el a következő kérést, hanem ugyanúgy elszáll. A párhuzamos kéréseknél meg lehet oldani, hogyha az egyik hibázik, akkor az összes többit leállítsa a rendszer, legalábbis ahol erre lehetőség van. Nyilván nem fogsz párhuzamosan select-en kívül más típusú kéréseket küldeni a szervernek. Ha adatbázissal kommunikálsz, akkor elég nyilvánvaló, hogy insert, update, delete esetében tranzakcióban használod sorosan. Én postgresql-t tolok most, és tárolt eljárásba teszek gyakorlatilag mindent, mert nekem úgy tisztább...
Olyan esetben jobbak az aszinkron kérések, ahol párhuzamos kérésekkel jobb eredményt tudsz elérni. Pl van több kérésed, és mindegyik egyenként sok időbe telik. Ha ezeket sorban futtatod, akkor az idők összeadódnak, ezzel szemben, ha párhuzamosan, akkor csak a leghosszabb ideig tartó kérésnek megfelelő időt kell kivárni.
Ha valamilyen alkalmazással szerver oldali eseményeket akarsz implementálni, akkor nodejs alapból jobb megoldás, mert eleve események vannak a szerveren, nem kell külön implementálni őket, mint mondjuk egy szinkron nyelv esetében. Tehát pl a munkamenet kezelés jóval egyszerűbb lesz benne. Ugyanígy bármilyen adat stream-elés sokkal egyszerűbb, ha történetesen socket.io-s kliens és a szerver között folyik az adat, akkor gyakorlatilag ugyanazzal az interface-el lesz dolgod szerver oldalon is nodejs esetében, nem lesz semmi új... Például chat alkalmazások, audio/video stream, realtime online játékok, stb... esetében ez mind nagyon jó.
Ha hagyományos weblapokat csinálsz, sima alkalmazásokat, ahol a kliens oldalon inkább csak html van, akkor jobb megoldás a php használata, mert nodejs-el körülményesebb lesz. Ezeknél nincs igazán szükség a nodejs előnyeire, viszont az aszinkron kérések miatt bonyolultabb lesz a kódod.
+1
Vagy ez a probléma nem egy
Kicsit zavaros, de ha jól értem, a válasz igen. Az egész alkalmazás egyetlen szálon fut, így ha éppen IO-ra várakozik, akkor addig semmilyen más eseményre nem tud reagálni.
Az aszinkronitás? Jó grafikus felületeknél, ahol természetes az eseményközpontú megközelítés. Szerveralkalmazásoknál, ha a várható terhelés akkora, hogy többszálú megvalósításban a szálak száma miatt elfogyna a RAM, jelenleg rákényszerülhetsz erre a megoldásra, azonban jó nem lesz, mert IO-t esemény alapon csinálni nehezen követhető kódhoz vezet.
Tetszik a cikk, nagyon
A yield terén még van ilyen: https://github.com/laverdet/node-fibers, thread témában meg ilyen: https://github.com/xk/node-threads-a-gogo (ez mondjuk ritkábban frissül, ahogy nézem).
Dehogynem!
yieldés társai, így Chrome Canary változatában pl már elérhető, ugyanígy a 0.11-es node.js-ben is használható már. A fiberset én is megemlítettem, de szerintem nagyon hekkelős, szóval nem is nagyon foglalkoztam vele. A gogo eszembe sem jutott :), de szerintem ezek az ötletek eleve halva születtek. Amíg nincsenek nyelvi szinten támogatva szálak, addig nem érdemes utánozni őket, csak félreértések származnak belőlük.Én is inkább afelé hajlok,
Szálak
Ja tisztában vagyok vele,
Js-ben amúgy a webworker is valami hasonló, mint a szálak, ha jól tudom:
http://ejohn.org/blog/web-workers/
Nem egészen
Ez abszolút szándékosan lett így tervezve pontosan azért, hogy ne keletkezzenek a szokásos szálkezelés körüli bonyodalmak a megosztott adatokkal.
Azért az adathozzáférés
A többszálú, szinkron megközelítés sokkal természetesebb, mint a Node.js-é.
(A fork és az IPC igen drága, így nem reális alternatíva az általános esetben, ráadásul nem küldhetsz át bármit socketen. Volt szerencsém socket leírókat átadni socketen keresztül, körülbelül egy hetem ment rá.)