
Adatbázisok verziókövetése Liquibase és Liquiface segítségével

Manapság minden felelős fejlesztő használ verziókövető-rendszereket. Minden kódunk minden változását nyomonkövetjük, felülvizsgáljuk, analizáljuk. Elterjedt gyakorlat, aminek hasznosságát senki nem vonja kétségbe. Miért is annyira nagyszerű dolog ez? Sok egyéb mellett például azért, mert pár másodperc alatt képesek vagyunk visszaállni alkalmazásunk egy korábbi verziójára, legyen az két nappal, vagy akár két évvel korábbi állapot. Ez így nagyon jól hangzik, de tényleg képesek vagyunk rá?
Vegyük a következő élethelyzetet: régóta fejlesztett szoftverünk egy régebbi verziójában felbukkan egy hiba. A feladat egy új kollégához kerül, aki eddig csak a szoftver friss verzióin dolgozott. A verziókövetőből checkout-olja a megfelelő kódot, elindítja az alkalmazást, majd némi fejvakarás közepette szétnéz az irodában: „Srácok, van valakinek ehhez a verzióhoz passzoló adatbázisa?”
Amire ezzel a kis példával rá szeretnék mutatni, az az, hogy az alkalmazás maga több a puszta kódnál, esszenciális része az adatbázis is. Ennek ellenére azt a szigorú fegyelmet, amivel a kódunkat karban tartjuk, sokszor valahogy nem érezzük kötelezően érvényesnek az adatbázisunkra. Pedig az adatbázis verziókövetésének sok előnye van:
- egy-egy commit-ban a kód változása mellett rögtön látszik, hogy hogyan változott az adatbázisséma;
- ha minden változás megvan, akkor a referencia-adatbázis bármikor felépíthető;
- ugyanígy a kód bármelyik verziójához tartozó adatbázis bármikor felépíthető;
- ha minden változtatást megfelelően standardizált módszerrel tárolunk, akkor az adatbázis frissítése automatizálható.
Ha elfogadjuk, hogy ez nekünk jó, akkor felmerül a kérdés, hogy mégis hogyan is tegyük ezt meg. Ahogy mondani szokás, a lehetőségek tárháza végtelen: az interneten keresgélve sok módszert, leírást, eszközt találhatunk ennek a megvalósítására. Én most csak egy eszközt mutatnék be, ami nálunk jól bevált.
Liquibase
A Liquibase egy ingyenes, nyílt forráskódú, adatbázisfüggetlen változáskövető eszköz, ami jól használható az elterjedt verziókövető eszközökkel. Lényege, hogy a szükséges adatbázismódosításokat nem közvetlenül az adatbázison hajtjuk végre, hanem minden változást struktúrált módon, egy ún. changelog fájlban tartunk nyilván. Ezt a changelog fájlt aztán a Liquibase parancssoros alkalmazás segítségével vagy kódból, a Liquibase Java API-val tudjuk érvényesíteni. Ennek használata a következő előnyökkel jár:
- a changelog fájl feltölthető verziókövetőbe, ezáltal megvalósíthatjuk adatbázisunk verziókövetését;
- a Liquibase számon tartja, hogy mely változások kerültek korábban már érvényesítésre adatbázisunkon, és csak a szükségeseket futtatja.
Hogyan is néz ki ez a gyakorlatban?
A megszerkesztett changelog fájlunk (ennek felépítéséről részletesen később lesz szó) futtatása egy Oracle adatbázison például a következőképpen néz ki:
liquibase \
--classpath=lib/ojdbc14.jar \
--driver=oracle.jdbc.OracleDriver \
--url=jdbc:oracle:thin:@localhost:1521:XE \
--username=user \
--password=secret \
--changeLogFile=changelogMaster.xml \
updateA fenti példában a --classpath-t kivéve minden paraméter kötelező. A --driver paraméter adja meg az adatbázishoz tartozó driver nevét, amit használni akarunk. A classpath az az útvonal, ahol a szükséges fájlokat tároljuk (mint pl. az adatbázis driver-e). A --changeLogFile paraméter adja meg a futtatandó changelog fájl nevét. Az --url paraméter a JDBC adatbáziskapcsolat-sztringje, ami (a --username és a --password paraméterekkel kiegészülve) az adatbázis eléréséhez szükséges minden információt tartalmaz.
Mint látható, futtatáskor elég sok adatot kötelezően meg kell adnunk. Hogy mégse kelljen ezt minden alkalommal begépelnünk, használhatunk egy properties fájlt, amiben ezeket a szükséges információkat felsoroljuk.
# liquibase.properties
classpath: lib/ojdbc14.jar
driver: oracle.jdbc.OracleDriver
url: jdbc:oracle:thin:@localhost:1521:XE
username: user
password: secret
changeLogFile: changelogMaster.xmlHa liquibase.properties-nek nevezzük el, és a Liquibase alkalmazással egy mappába tesszük, akkor futtatáskor automatikusan ezeket az adatokat fogja használni. Más esetben a következő szintakszissal érhető el:
liquibase --defaultsFile=<útvonal>/<fájlnév>.properties updateHa mindent megfelelően adtunk meg, akkor a Liquibase az első sikeres futtatás legelején létrehoz az adatbázisunkban két táblát DATABASECHANGELOG és DATABASECHANGELOGLOCK néven. Ez az egyetlen alku, amit a Liquibase használatához meg kell kötnünk: erre a két táblára szüksége van mindenképpen. Cserébe az adatbázis tudja magáról, hogy melyik változás lett már futtatva rajta és pontosan mikor.
A changelog fájl felépítése
Eredetileg a changelog fájlok csak XML típusúak lehettek. Ma már a Liquibase támogatja emellett a YAML, JSON és a (speciális kommentekkel ellátott) SQL típusokat is. Jelen cikkben az XML típust használva fogom bemutatni egy changelog fájl felépítését.
A changelog fájl tartalmazza a változásokat (changes/refactorings), amiket végre szeretnénk hajtani. Minden változtatáshoz, amit megtehetünk tartozik egy Liquibase change. Ezeket a change-eket changeSet-ekbe kell szerveznünk. Minden changeSet kötelezően rendelkezik egy id és egy author paraméterrel, valamint tartalmaz egy vagy több change-et. change-ek csak changeSet-en belül létezhetnek.
Egy példán keresztül talán szemléletesebb, hogy is működik ez. Tegyük fel, hogy üres adatbázisunkban létre szeretnénk hozni egy user táblát, id, login és created mezőkkel. Ebben az esetben a changelog fájlunk a következőképpen fog kinézni:
<?xml version="1.0" encoding="utf-8" standalone="no" ?>
<databaseChangeLog
xmlns="http://www.liquibase.org/xml/ns/dbchangelog"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-2.0.xsd"
>
<changeSet author="botond" id="create_user_table">
<createTable tableName="user">
<column name="id" type="integer"/>
<column name="login" type="VARCHAR(255)"/>
<column name="created" type="TIMESTAMP"/>
</createTable>
</changeSet>
</databaseChangeLog>Ez a példa csak egy a sok támogatott change közül: az alapvető műveletektől, mint tábla/oszlop létrehozása, törlése, az elsődleges és külső kulcsok, különböző megszorítások létrehozásán át egészen szekvenciák, indexek és tárolt eljárások létrehozásáig, módosításáig (és tovább) terjed a lista.
Adattartalom kezelése
A Liquibase nem áll meg a sémadefiníciós utasításoknál. Tegyük fel, hogy az előbb létrehozott táblánkba szeretnénk felvenni egy developer nevű felhasználót, hogy tudjuk tesztelni a fejlesztett alkalmazásunkat. Ezt persze megtehetjük bármelyik adatbáziskezelővel, de ilyenkor a többi fejlesztő is arra kényszerül, hogy kézzel hozza létre a felhasználót. Ehelyett használhatjuk az insert utasítást. Ekkor a changelog fájlunk a következőképpen fog kinézni:
<?xml version="1.0" encoding="utf-8" standalone="no"?>
<databaseChangeLog
xmlns="http://www.liquibase.org/xml/ns/dbchangelog"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-2.0.xsd"
>
<changeSet author="botond" id="create_user_table">
<createTable tableName="user">
<column name="id" type="INTEGER"/>
<column name="login" type="VARCHAR(255)"/>
<column name="created" type="TIMESTAMP"/>
</createTable>
</changeSet>
<changeSet author="botond" id="insert_developer_user">
<insert tableName="user">
<column name="id" value="1" />
<column name="login" value="developer" />
<column name="created" valueDate="2013-07-30T16:30:42" />
</insert>
</changeSet>
</databaseChangeLog>Az egyedi insert-ek mellett lehetőségünk van nagyobb adatmigrációra is a loadData és a loadUpdateData utasításokkal. Ezek az utasítások – az oszlopok egyeztetése után – képesek CSV fájlokból feltölteni az adatbázist.
Előfeltételek megadása
Az előbb láttunk egy példát arra, hogy tesztfelhasználót hoztunk létre Liquibase használatával. Igen ám, de mi a helyzet, ha ez az igény csak később jelentkezett? Elkészítettük a táblát létrehozó utasítást, feltöltöttük verziókövetőbe, a fejlesztő kollégák futtatták, és tegyük fel, van, aki már létre is hozott magánál developer nevű felhasználót. Nyilván szeretnénk elkerülni, hogy problémát okozzunk egy újabb developer nevű felhasználó létrehozásával. Szerencsére a Liquibase erre is kínál megoldást, a preConditions elem használatával. Minden changeSet elején definiálhatunk előfeltételeket, hogy milyen esetben futtassa a Liquibase az adott changeSet-et. A mi esetünkben például vizsgálhatjuk, hogy a user táblában van-e már developer nevű felhasználó. Ezzel kiegészülve a changelog fájlunk már így néz ki:
<?xml version="1.0" encoding="utf-8" standalone="no"?>
<databaseChangeLog
xmlns="http://www.liquibase.org/xml/ns/dbchangelog"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-2.0.xsd"
>
<changeSet author="botond" id="create_user_table">
<createTable tableName="user">
<column name="id" type="INTEGER"/>
<column name="login" type="VARCHAR(255)"/>
<column name="created" type="TIMESTAMP"/>
</createTable>
</changeSet>
<changeSet author="botond" id="insert_developer_user">
<preConditions onFail="MARK_RAN">
<sqlCheck expectedResult="0">SELECT COUNT(*) FROM user WHERE login = 'developer'</sqlCheck>
</preConditions>
<insert tableName="user">
<column name="id" value="1" />
<column name="login" value="developer" />
<column name="created" valueDate="2013-07-30T16:30:42" />
</insert>
</changeSet>
</databaseChangeLog>Jelen esetben az történt, hogy az sqlCheck elem segítségével azt mondtuk, a fenti lekérdezés futtatásakor a várt érték a 0. Ha ezt az értéket kapjuk, a changeSet futtatásra kerül. Az sqlCheck mellett számos másik elemet is használhatunk, az and és or elemekkel pedig összetett kifejezésekké kombinálhatjuk őket.
Vegyünk észre még egy érdekességet: a preConditions elemnek megadhatjuk az onFail paraméter segítségével, hogy mi történjen, ha a feltétel nem teljesül. Jelen esetben azt mondtuk a MARK_RUN értékkel, hogy ha az előfeltétel nem teljesül, akkor hagyja ki a changeSet-et és jelölje meg futtatottként. Mondhattuk volna azt is, hogy a teljes changelog futtatását szakítsa meg (ez az alapértelmezett), de azt is, hogy ezúttal hagyja ki, de következő futtatásnál próbálja újra.
Környezet
Az előbb láttuk, hogyan írhatunk feltételtől függő change-t fejlesztéshez használt felhasználó létrehozására. De mi a helyzet abban az esetben, ha a feltételünk nem fogalmazható meg ilyen egyszerűen SQL utasítás formájában? Például hogyan tudnánk megoldani, hogy a fejlesztéshez használt felhasználónk csak a fejlesztői adatbázisokon jöjjön létre? Az ilyen helyzetek megoldására létezik a changeSet-ek context paramétere. Ennek segítségével minden changeSet-re külön beállíthatjuk, hogy milyen környezetben szeretnénk, ha lefutna. A changelog fájl futtatásakor pedig (akár parancssorosan, akár Java API-val futtatjuk) megadhatjuk, hogy milyen környezetben vagyunk éppen.
Példánknál maradva tehát, ha szeretnénk egy „development” nevű környzetet kialakítani, akkor changelog fájlunk a következőképpen alakul:
<?xml version="1.0" encoding="utf-8" standalone="no"?>
<databaseChangeLog
xmlns="http://www.liquibase.org/xml/ns/dbchangelog"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-2.0.xsd"
>
<changeSet author="botond" id="create_user_table">
<createTable tableName="user">
<column name="id" type="INTEGER"/>
<column name="login" type="VARCHAR(255)"/>
<column name="created" type="TIMESTAMP"/>
</createTable>
</changeSet>
<changeSet author="botond" id="insert_developer_user" context="development">
<preConditions onFail="MARK_RAN">
<sqlCheck expectedResult="0">SELECT COUNT(*) FROM user WHERE login = 'developer'</sqlCheck>
</preConditions>
<insert tableName="user">
<column name="id" value="1" />
<column name="login" value="developer" />
<column name="created" valueDate="2013-07-30T16:30:42" />
</insert>
</changeSet>
</databaseChangeLog>A properties fájlunk pedig így néz ki:
# liquibase.properties
classpath: lib/ojdbc14.jar
driver: oracle.jdbc.OracleDriver
url: jdbc:oracle:thin:@localhost:1521:XE
username: user
password: secret
changeLogFile: changelogMaster.xml
contexts: developmentHa több környzetet is kialakítottunk, futtatáskor vesszővel elválasztva többet is felsorolhatunk. Amelyik changeSet-hez nem adtunk meg környzetet, az minden esetben le fog futni, aktuális környezettől függetlenül. Ha futtatásnál nem adtunk meg semmilyen környezetet, akkor minden changeSet lefut, context paraméterüktől függetlenül.
Adatbázisfüggetlenség
Korábban említettem, hogy a Liquibase adatbázisfüggetlen. Ez így nem teljesen igaz, valójában inkább csak annak tűnik, hiszen több mint 15 adatbázist támogat, többek között MySQL-t, Oracle-t, SQLite-ot, PostgreSQL-t stb. Éppen ez az egyik indok, amiért érdemes az XML formátumú changelog fájlt használni: a Liquibase az éppen használt adatbázis függvényében állítja össze a megfelelő konkrét SQL utasításokat. Így ugyanazt a changelog fájlt tudjuk használni még olyan extrém esetekben is, ha pl. az éles rendszer Oracle adatbázison, a fejlesztői rendszerek MySQL adatbázison, az integrációs tesztek pedig Derby-n futnak.
De nem veszítjük el ezt az adatbázisfüggetlenséget azáltal, hogy oszlopok létrehozásakor konkrét típusokat adunk meg? A válasz az, hogy sajnos de. Hiszen pl. Oracle esetén VARCHAR helyett VARCHAR2 használata javasolt, a PostgreSQL használ BOOLEAN típust, míg sok más adatbázis nem és így tovább. Ám erre a problémára is van megoldás.
A Liquibase a property elem használatával támogatja paraméterek dinamikus behelyettesítését. Ez a gyakorlatban azt jelenti, hogy a környezettől és/vagy adatbázistól függően deklarált property-re a changelog fájlban bárhol hivatkozhatunk a ${<property név>} szintaxissal, akár típusok megadásánál is. Tehát ha pl. Oracle-lel és Apache Derby-vel is kompatibilissé szeretnénk tenni korábbi changelog fájlunkat, akkor azt például a következőképpen tehetjük meg:
<?xml version="1.0" encoding="utf-8" standalone="no"?>
<databaseChangeLog
xmlns="http://www.liquibase.org/xml/ns/dbchangelog"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-2.0.xsd"
>
<property name="integer" dbms="oracle" value="NUMBER(38,0)" />
<property name="integer" dbms="derby" value="BIGINT" />
<property name="varchar" dbms="oracle" value="VARCHAR2" />
<property name="varchar" dbms="derby" value="VARCHAR" />
<changeSet author="botond" id="create_user_table">
<createTable tableName="user">
<column name="id" type="${integer}"/>
<column name="login" type="${varchar}(255)"/>
<column name="created" type="TIMESTAMP"/>
</createTable>
</changeSet>
<changeSet author="botond" id="insert_developer_user" context="development">
<preConditions onFail="MARK_RAN">
<sqlCheck expectedResult="0">SELECT COUNT(*) FROM user WHERE login = 'developer'</sqlCheck>
</preConditions>
<insert tableName="user">
<column name="id" value="1" />
<column name="login" value="developer" />
<column name="created" valueDate="2013-07-30T16:30:42" />
</insert>
</changeSet>
</databaseChangeLog>Mi az, amit a Liquibase nem tud?
A fent leírtak még csak a jéghegy csúcsa: írhatnék még arról, hogy milyen hasznos, hogy a legtöbb changeSet adatbázison történő futtatás után is automatikusan visszavonható a rollback paranccsal. Vagy arról, hogy milyen egyszerű már meglévő adatbázist is Liquibase alapúvá tenni a generateChangeLog utasítással. Vagy hogy futtatáskor jelzi, ha valamelyik changeSet tartalma az utolsó futás óta megváltozott. De ezekre most nem térek ki, mert akinek sikerült felkelteni a figyelmét az eddigiekkel, az valószínűleg ezekre a funkciókra már hamar rá fog találni, ezért inkább rátérnék arra, hogy mik a Liquibase hiányosságai, hátrányai.
Hátránynak lehet esetleg tekinteni, hogy meg kell barátkozni a korábban említett két új tábla létezésével. Emellett ugye meg kell ismerkedni a Liquibase saját „nyelvével”. Ezen kívül más hátrány nálunk nem ütötte fel a fejét, ebből is látszik, hogy gyakorlatilag csak előnyökkel jár a használata.
Ami hiányosságot esetleg lehet említeni, az sem igazán komoly probléma: az XML szerkesztése általában lassúnak érződik. Hiába a megfelelő XSD és IDE használata, típusok értékét például így sem lehet automatikusan kiegészíteni, ráadásul gyakran nagyon hasonló utasításokat kell sokszor egymás után írni, és ilyenkor nagyon csábító a copy-paste használata, amivel könnyű apró hibákat bevezetni. Az itt leírtak lényegében mind visszavezethetőek egyetlen hiányosságra: a Liquibase-nek nincs grafikus felülete. Ez az, amit most megpróbálunk pótolni, ugyanis létrehoztunk egy NetBeans plugin-t, amivel kényelmesen, grafikus felület segítségével használhatjuk a leggyakoribb Liquibase funkciókat.
Liquiface
A Liquiface elnevezés úgy érezzük, jól kifejezi, hogy próbálunk „arcot adni” a Liquibase-nek. A projekt alapötlete pár éve született egy a Webstar Csoport-on belüli 24 órás FedEx nap nevet viselő programozási versenyen, később pedig belső önképzésként folytattuk (Takács Viktor, Marics Tamás és én, Adorján Botond). Az általunk megálmodott széles funkcionalitás sok részére azonban még így sem jutott idő. Szerencsére a cégvezetés is hasznosnak látta a projektet, ezért kaptunk a megvalósításra további erőforrásokat, így végül eljutottunk a most bemutatkozó 1.0-ás verzióig.
Mit tud a Liquiface?
Röviden megfogalmazva igyekszik kényelmi funkciókkal kiegészíteni a Liquibase eszköztárát. Ezt például azzal éri el, hogy a közvetlen XML szerkesztés helyett kényelmesen, varázslók által vezetve hozhatjuk létre a leggyakoribb Liquibase change típusokat. Ennek köszönhetően azok is könnyen megismerkedhetnek a Liquibase hasznosságával, akiknek nincs kedvük vagy idejük a szerkezetét megtanulni.
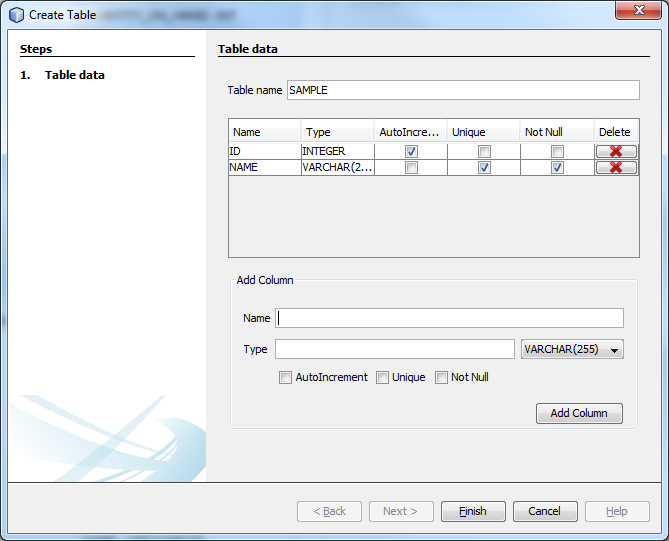
Új tábla létrehozása
Ennyinél azonban nem álltunk meg: hiszen nem csak az a fontos, hogy képesek legyünk elkészíteni egy Liquibase change-t, legalább annyira hasznos, ha rögtön látjuk is, hogy mit csináltunk. Ezért a Liquiface szimulálja nekünk az adatbázis struktúráját, megjelenítve benne minden táblát és kapcsolatot. Mivel adatbázisunk nagyra nőhet, ezért lehetőség van többfajta szűrésre és bizonyos megjelenítések kikapcsolására is.
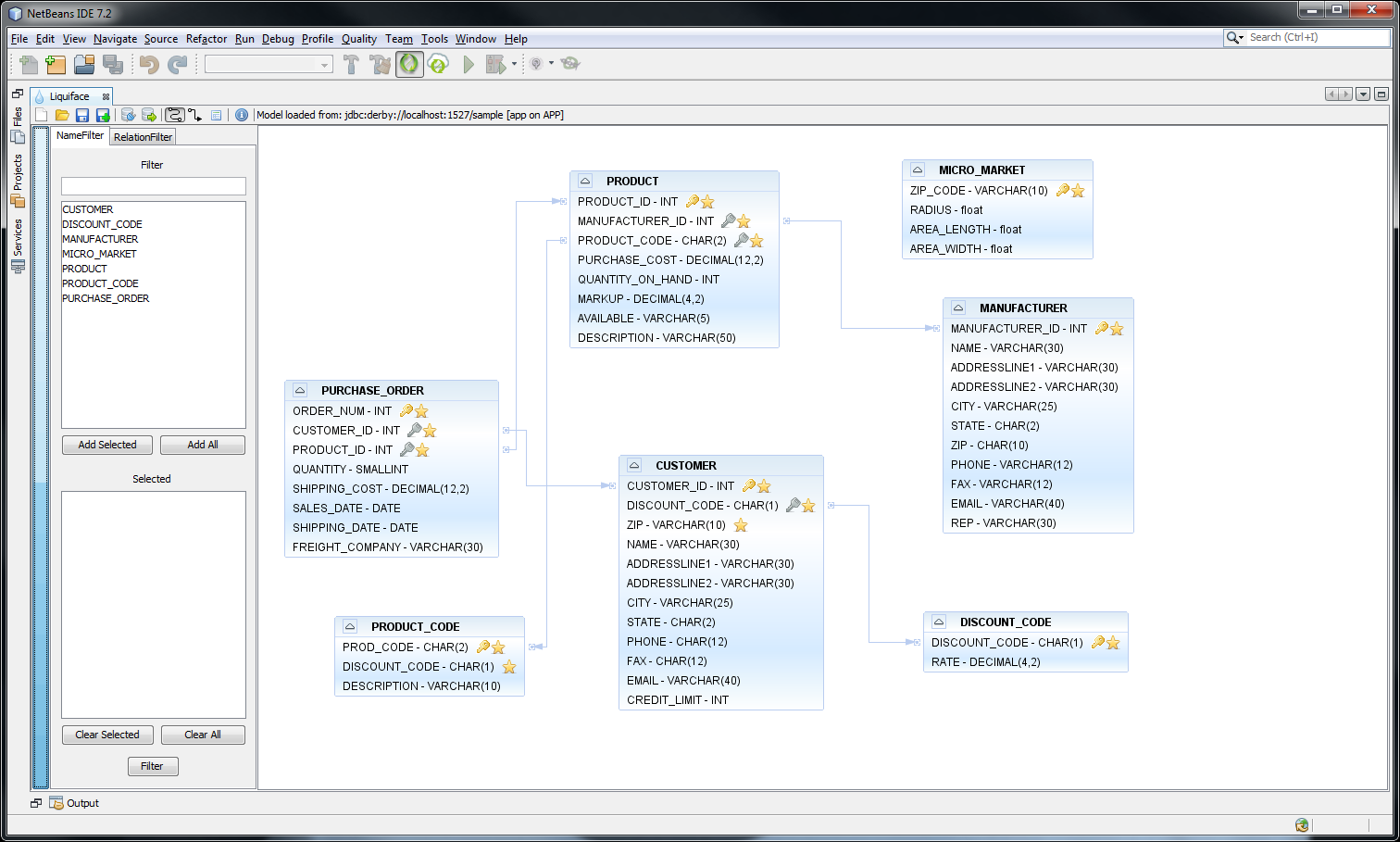
Adatbázis megjelenítése Liquiface-en
Ha pedig készen vagyunk a szerkesztéssel, változtatásainkat elmenthetjük új fájlba vagy hozzáadhatjuk már létezőhöz. Emellett a NetBeans-ben definiált adatbáziskapcsolatok segítségével lehetőségünk van arra is, hogy rögtön adatbázison futtassuk a változásokat.
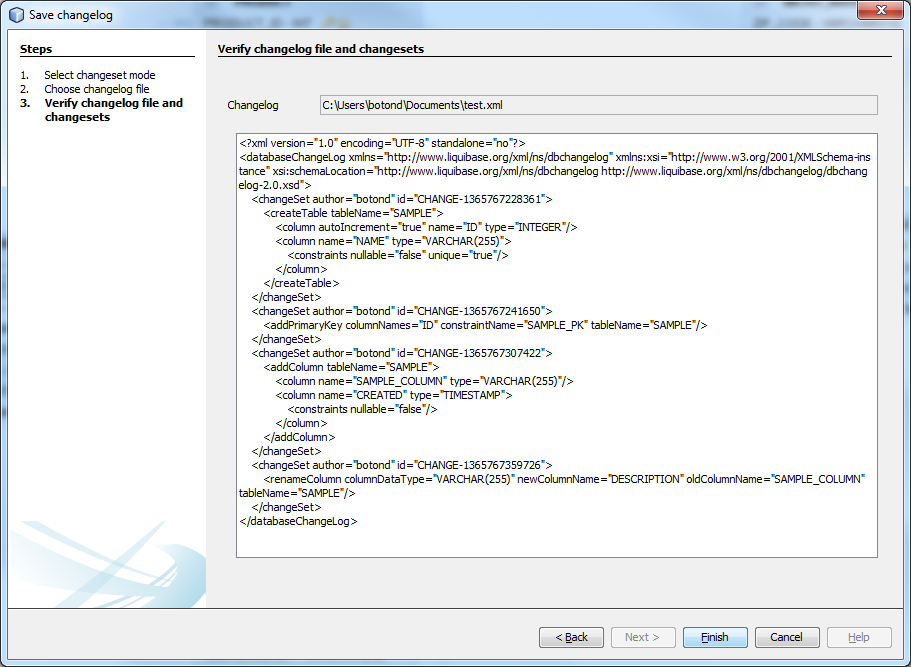
Changelog mentése
A most kiemelt funkciók csak a Liquiface által nyújtott könnyebbségek sarokkövei. Akit részletesebben érdekel, pontosan milyen egyéb képességekkel vérteztük fel, az tovább tájékozódhat a Liquiface használati útmutatóban vagy letöltheti a NetBeans portálról, és maga is kipróbálhatja.
Összefoglalás
Az adatbázisok verziókövetésének általános elveitől a Liquibase eszközön keresztül eljutottunk egészen a Liquiface plugin-ig. Én mindenkit arra biztatnék, aki még nem teszi, kezdje el verziókövetni az adatbázisok változásait is. Az is van olyan fontos, mint a kód, ne kezeljük mostohán! A bemutatott eszközök pedig erre egyszerű és gyors módot szolgáltatnak. Remélem, aki még nem találkozott velük, annak sikerült felkeltenem az érdeklődését! Aki pedig kipróbálja a Liquiface-t, attól azt kérném, segítse a munkánkat: mondja el nekünk véleményét, meglátásait, hogy olyan irányba folytathassuk a plugin fejlesztését, ami minden felhasználójának megelégedésére szolgál!
A bélyegképen Tony Sava fényképe látható.
■




Nagyon jó hogy kikerült ide
Az elmúlt hónapokban néztünk végig pár adatbázis verziókezelőt, és nálunk is a liquibase tűnt a legkézenfekvőbb választásnak. Versenyben volt még a flywaydb, illetve a RoR és Play megoldása is felvetődött. Végül azonban egyik sem lett, hanem írnom kellett egy sajátot, nem kis erőforrásbefektetéssel :) Lényegében a liquibase ötletére épül, tehát igazából ezzel nem volt baj.
És akkor ami még nekem tetszett:
- Van maven/ant pluginja, integrálható CI rendszerekkel. Ez egyrészt egyszerűbbé teszi a dev környezetek karbantartását, másrészt az elrontott change-ek hamar kijönnek.
- Az utolsó mondathoz tartozik egy fontos tulajdonsága: támogatja a rollbackTestinget is, ami annyit tesz, hogy egymás után végrehajtja az upgrade, rollback, upgrade change-eket egymás után. Ez szerintem egy nagyon hasznos feature.
Nálunk ami hátrányként kijött:
- Produktion db-t elérő gépen ott kell legyen a liquibase. Bármilyen blődül is hangzik ez, vannak környezetek, ahol ez nem megy valami egyszerűen. Nálunk ez volt az a pont, amin a liquibase megbukott, de itt megbukott volna minden egyéb tool is.
- A statement separatorokkal itt-ott trükközni kell, pl az oracle tároltjaival kellett kicsit masszírozni
- Van egy kapcsolója, ami 1 marhanagy sql fileba tolja ki az upgrade és a rollback utasításokat. Itt emlékeim szerint a tranzakciókkal volt egy kis gubanc, de most fejből már nem emlékszem pontosan.
És még pár gondolat a rollbackről. Triviális, de nem minden adatbázis módosítás visszavonható. Tehát pl egy
delete table-nek nem valid rollbackje acreate table, hiszen a táblában valószínűleg olyan adatok voltak, amik kellettek, és/vagy constraintet sért(enének), ha nincsenek meg. És adott esetben production db-t is kellhet rollbackezni (pl az új verzió bevezet valami bugot). Persze játszótér db-kre önmagában acreate tableis jó (lehet), de éles adatbázisoknál kicsit körültekintőbben kell eljárni a rollback iránnyal, ebben az esetben pedig már kicsit bonyolult megoldások tudnak születni :)Mindenesetre nekem bejött a liquibase és én is szívesen ajánlom. A db verziózást meg pláne :)
Videó
Nagyon jó cikk lett, mèg ma
Kérdések
Megoldható-e következő: egy szerveren belül a teszt- és bétaadatbázisnak saját prefixe van, pl. teszt_adatok, beta_adatok. Ha a teszt_adatokon belül végzünk módosításokat, azt át lehet-e vinni a béta megfelelő tábláiba? Megoldható-e a változások másik szerverre való átmásolása?
Ez mennyire reális szituáció?
Tegyük fel, hogy van egy szoftverünk, aminek van egy publikus változata. Ez már kint van fél éve. De készül a következő verzió már 7 hónapja. Viszont jó lenne tudni, hogyan működik az alkalmazás éles adatokkal is. Szerintem ez elég reális.
Ez mennyire reális szituáció?
Olyan alkalmazás esetén, ami több főverziót is megél, szerintem reális igény lehet régebbi verziók esetén is pl. a kritikus hibák javítása.
Bevallom, itt nem teljesen értem a kérdést. Ha a teszt- és bétaadatbázis saját prefixe alatt azt érted, hogy külön sémában vannak, akkor a válasz az, hogy minden change típus támogatja séma megadását is.
Ha a teszt_adatokon belül hajtasz végre módosítást, azaz liquibase használata nélkül, valamilyen adatbáziskezelő segítségével módosítod az adatokat, akkor azokat a változásokat a másik adatbázison is ugyanúgy kézzel kell végrehajtanod. Viszont ha a módosításokat liquibase segítségével hajtod végre, akkor egyszerűen annyi a dolgod, hogy ugyanazt a changelog xml-t futtatod a másik adatbázison is.
Ugyanígy oldható meg a másolás is.
Tekints a changelog fájlra úgy, mintha minden egyes sql query-t, ami az adatbázis struktúráját, esetleg néhány fontos adattartalmát módosítja, szekvenciálisan eltárolnád néhány metaadattal együtt.
Plain sql-lel szemléltetve: ha írsz egy create table-t és utána két insertet és ezeket elmented egy sql fájlba, akkor azt az sql szkriptet utána bármilyen adatbázison futtathatod, működni fog. De attól, hogy egy adatbázison futtatsz egy harmadik insertet, az még nem fog bekerülni az előbb megírt sql szkriptedbe.
Pontosítok
teszt_adat1db- tábla 1
- tábla 2
teszt_adat2db- tábla 1
- tábla 2
Ezeken végzek módosítást:
ALTER TABLE teszt_adat1.tabla1 ...ALTER TABLE teszt_adat2.tabla1 ...Megoldható-e, hogy legenerálja a következőt:
ALTER TABLE beta_adat1.tabla1 ...ALTER TABLE beta_adat2.tabla1 ...?Létezik a liquibasenek egy
Ha így generálunk egy changelog fájlt, update esetén van lehetőség arra, hogy valójában ne futtassa a változásokat, csak írja ki a generált sql-t. Hogy ilyenkor a sémanevet is beleveszi-e, annak utána kellene nézni.
Köszönöm a válaszokat!
Ez mennyire reális szituáció?
Itt ha adatokra gondolsz, akkor ez a tool nem arra való, hogy migráljon. Ha
alter table-re, mint lejjebb írtad, akkor az a lényege, hogy az xmlben írd le a változtatásaidat, és akkor akárhány db-re ki tudod tenni ugyanazt. Ha ilyen tool mellett valaki kézzel masszírozgatja a db-t, az nádpálcás verést kap :)Több verzió vs. continous integration
A continous integration, ill. a continous delivery ezen verziók számának csökkentésén dolgozik (ideális esetben 1-re).
Még csak gyorsan átfutottam.
Migrációk vs adatbázis verziókezelés
Ez az eszköz elsősorban nem
Ettől függetlenül a sima sql szkriptekkel szemben megvan az az előnye, hogy az adatbázisban nyílvántartja, mik azok a változások, amik már lefutottak. Ez a gyakorlatban azt jelenti, hogy nem kell keresgélni, hogy melyik az új szkript, amit futtatni kell, ill. nem fordulhat elő olyan probléma, hogy ugyanazt a szkriptet véletlenül többször futtatjuk. Ebből kifolyólag pedig könnyedén automatizálható a változások futtatása: pl. a liquibase-maven-plugin használatával elérhető, hogy az alkalmazás futtatásakor automatikusan futtassa a liquibase changelogot is.
Séma migráció is van
Amit nem tudok megoldani az az adatbázis tartalmának tehát pont az általad említett adatmigrációk normális megvalósítása verziókezelten, amin ezek szerint a Liquibase sem segítene?
Nem használtam még az általad
Mint írtam, léteznek benne lehetőségek az adatok manipulálására, de ezek inkább néhány kritikus adat felvitelére, esetleg tesztadatok készítésére alkalmasak, teljes adattartalom verziókövetésére nem használnám.
Adat migráció
Milyen előnyökkel jár ahhoz
Az egyik előny nyilván az adatbázis függetlenség. Ezen kívül kérdem...
Reméltem, hogy valaki
Az egyik előny nyilván az
Akár különböző típusú adatbázisokat, akár ugyanolyan típusú, de különböző adattartalmú adatbázisokat értesz adatbázisfüggetlenség alatt, szerintem mindkét esetben elég nagy előnye van a dumppal szemben. Nálunk van olyan projekt pl. ahol a fejlesztők, a tesztrendszerek és az éles rendszer mind különböző oracle adatbázisokat használnak, miközben az integrációs tesztek memóriában felhúzott derby adatbázison futnak. Ez nem olyasmi, amit dump használatával könnyű lenne elérni. :)
Emellett például az is előny lehet, hogy liquibase esetén a verziókövető egyértelműen tudja jelezni a változásokat, míg mondjuk egy bináris oracle dump esetén csak annyit látsz, hogy változott a fájl.
Hát én most pgsql-re
Dump vs db verzió toolok
- Hogy állsz vissza előző adatbázisverzióra, ha már futott a rendszer az új adatbázison?
- Hogy oldod meg, hogy bizonyos változások csak bizonyos környezeten hajtódjanak végre? Pl tesztuserek
- Hogyan akadályozod meg, hogy 2x ne fusson rá a db-re ugyanaz a változtatás többszöri futtatásra? (tegyük fel, hogy automatikus deploy van)
- Hogyan teszteled, hogy mely változtatások futnának le az adatbázison anélkül, hogy módosítanád azt?
A liquibase, vagy egy hasonló tool ezekre a kérdésekre ad választ a dump tudásán túl. És még biztos van, ami nem jutott most eszembe.
- Hogy állsz vissza előző
- Hogy oldod meg, hogy bizonyos változások csak bizonyos környezeten hajtódjanak végre? Pl tesztuserek
Ezt nem értem miben válasz a
Ha vissza kell állni egy verziót az éles adatbázissal, akkor azon nem segít, hogy van teszt db.
Ugyanúgy a másodikra se válasz. Arra az lehet esetleg válasz, hogy van egy másik db csomag is, amit deven, teszt környezetben még lefuttatok, élesen meg nem, ki se release-elek. De ha több ilyen környezeted van, akkor már az is elég macerás.
Hát úgy kell fejleszteni,
Esetleg tudsz konkrét példát mondani arra, hogy egy rendesen tesztelt rendszerrel vissza kellett állni? Nem hiszem, hogy ez olyan sűrűn előfordulna...
Nem emlékszem, hogy lett
De remélem itt se kell egy tervezetlen downgrade-et megélnünk, mert az minden szempontból horror lenne :)
Performanciát általában nem
Ja, én is erre gondoltam,
A Facebook jelenleg talán a
Feature switcheket sok nagy
Külön teszt és külön éles
a teszt adatbázisnál a
No majd belenézek.
Leírtad a legnagyobb problémát
Ez a lépés egy rizikó faktor, mert 1) nincs verziókezelve a kód 2) manuálisan kell végrehajtani a folyamatot (hiba jöhet elő, nem lehet pontosan a korábban már tesztelt folyamatot futtatni). Persze a legtöbb probléma csapat esetén jön elő.
Mekkora rendszerre
Plusz ha egynél több fejlesztő dolgozik az oldalon, akkor a végső commitot nem feltétlenül az tolja, aki a feature-t fejlesztette. Pl. az egyik fejlesztő megcsinálja az A feature-t, amihez át kell neveznie pár oszlopot, a másik megcsinálja a B featuret, amihez módosít egy mezőtípust, aztán a release manager feladata lesz az A és B brancheket, meg még másik harminchármat összemergelni és tesztelni a végeredményt, amihez nyilván egyik fejlesztő DB dumpja sem megfelelő, és ha neki kézzel kell reprodukálnia az összes sémamódosítást, akkor jövő ilyenkorra se lesz új release.
Plusz ha van egy gép, amin az automatizált tesztek futnak, arra nagyon nem szeretnél bizonytalan eredetű és tartalmú adatbázisdumpokat feltölteni, mert utána már fogalmad sem lenne, hogy mit is tesztelsz tulajdonképpen.
Ja, hát kis rendszereket
Mint közös külső erőforrás,
Szerintem ritka, hogy
Ha összeakadnak a
Szétesik (illetve a későbbi
Több adatbázismotor
Az logikus, hogy az integrációs tesztek mondjuk egy in-memory adatbázison futnak, de az hogy a fejlesztői rendszer és az éles adatbázis különböző legyen, számomra elég fura. Sajnos messze vagyunk attól, hogy az adatbázismotorok egymással csereszabatosak legyenek. Így viszont egyes bugok lehet, hogy csak prodban jönnek ki. Ha feltesszük, hogy a QA is Oracle-t használ, akkor jobb a helyzet, de ekkor a fejlesztő még mindig nem tudja debuggolni a hibát. De még ha nincs is bug, az adatbázisok teljesítménye alap esetben is különböző, a fejlesztőnek így nincs semmi esélye a teljesítmény tesztelésre.
Simán lehet memory db-en
És a production Oracle-höz
Tudtommal fejlesztésre
Persze nem kizárt, hogy ez is megváltozott az elmúlt években.
Dev licenc nem jár, de
Lusta vagyok utánanézni, de
(előbbi lehet, hogy csak non-profit környezetben)
A felhozott példa szerencsére
Mennyire kompatibilis ez a
Olyan dolgokra gondolok, hogy pl. több ágat összemergelni, és merge conflictot feloldani a changelog-ban, vagy checkout-nál automatikusan átalakítani az adatbázis szerkezetét (és esetleg adatait) a branch-nek megfelelő formára, stb... Az egy dolog, hogy lehet committálni a változásokat, de ha nem változik minden automatikusan a kóddal együtt, akkor elég nehézkes lesz a használata...
Olyan dolgokra gondolok, hogy
Ezt miért szeretnéd? És hol,
Ha nem lett volna egyértelmű, akkor dev adatbázisról van szó, amin az integrációs teszteket futtatod, és nem élesről... Elvileg egy post-checkout hook-kal megoldható, de ha az nem menne, akkor az integrációs tesztek futtatása előtt a changelog-ról készített hash ellenőrzésével is ki lehet deríteni, hogy tényleg a jelenlegi kódhoz tartozó adatbázis szerkezetről van e szó.
Pontosan arra, hogy össze lehet e mergelni egyszerűen.
Ha nem lett volna egyértelmű,
Imho baromi lassú, ha a teszt
Miért lassú? Vagy mi lassú?
Hogy biztos legyen, hogy egyről beszélünk, leírnám én mi alatt mit értek :)
Unit testing: Olyan teszt, ahol célzottan a kód egy részét teszteljük (class, method stb), körülötte mindent kimockolva. DB-t is, így ez nem érdekes most. Ez jellemzően a fejlesztői gépen, vagy CI serverben, a build részeként történik.
Component testing: Ugyanaz, mint a unit teszt, csak real objectekkel. A kichekoutolás miatt én arra tippelek, hogy valójában erre gondolsz. Itt jellemzően nulláról alá tolunk egy db-t (sok esetben valami in-memoryt).
Integration testing: Telepített környezetet tesztelünk, ahol az alkalmazás minden része össze van kötve, a db is alatta van stb. Fontos, hogy ezekben a környezetekben már jellemzően manuális teszt is zajlik, ezért nem illik csak úgy legyilkolni tesztadatokat. Ez visszavezet ahhoz amit az elején is mondtam, hogy csak úgy különböző verziók között rángatni a db-t nem lehet, mert igen nehéz megoldani, hogy egy A->B->A verzióváltás ne járjon adatvesztéssel (gyakorlatilag nem lehet).
A legtöbb alkalmazásnál az működik, hogy van egy környezet a prodban épp kint lévő verziókkal, az esetleges patcheket ebben a környezetben teszteljük. Illetve van egy másik, ahol a következő tervezett prod verzió tesztelése zajlik. Ennek megfelelő db verziókkal, amik ezek miatt mindig egy irányba (előre) közlekednek. Meg persze a fejlesztői környezetek, snapshot verziókkal, ahol szabadabban lehet rugdosni a db-t is.
Ahol különböző ügyfeleknek különböző ütemben, eltérő feature settel release-elgetjük ugyanazt az appot, ezért N branch kell egyszerre... Az már sok kérdést felvet, pl hogy jó-e, fenntartható-e ez a modell :)
Természetesen nem jár rituális kivégzéssel, ha esetenként ezek a határok összemosódnak :), pl nekünk van olyan integrációs tesztünk, ami telepített, de mockos környezetben fut. De ami fontos, hogy a tesztek mindig konkrét, előre definiált adatokkal történnek, beleértve a db-t is, azokat a teszt a setup fázis alatt összeállítja magának, majd lefut a teszt, lefutnak az assertek, a teardownban pedig eltávolítja ezeket. Máskülönben nem lesz megbízható a teszt.
Jó hosszúra eresztettem... A lényeg, hogy ahogy látszik is, sokkal hamarabb fogsz koncepcionális problémába ütközni, minthogy egy jó tool (a liquibase szerintem az) megengedné-e, hogy jobbra-balra tekergesd a db-t.
Nekem ha bármi lassabb, mint
Nálam az az integrációs teszt, ami megmutatja, hogy a programod jól illeszkedik a környezetébe. Akár még az aktuális programnyelv beépített feature-eihez is csinálhatsz integrációs tesztet, ha biztos akarsz lenni, hogy jól működnek, és nincsen self-test és/vagy gyenge a dokumentáció hozzájuk... (Egyébként ezzel rengeteg időt lehet spórolni bármilyen verzió váltásnál vagy db migrációnál...)
Az én esetemben azért számít a sebesség, mert nem szívesen írok unit teszteket az adatbázis nyelvén, amikor stored procedure-öket, view-okat tesztelek. Inkább integrációs tesztekkel szoktam megnézni, hogy minden okés e. TDD nélkül neki se lehet kezdeni stored procedure írásának, mert annyira rosszul debuggolható... Egyébként is el lehetne felejteni a debug-ot, a TDD sokkal egyszerűbb...
A liquibase előnyeinek nagy
A liquiface-el használva működőképes megoldás lehet a liquibase, viszont magában nekem nem szimpatikus, nem szeretek config fájlokat gépelni, inkább kattintgatós típus vagyok.
Közben jobban
Miért nincs?
A schema szerkesztését meg
Az event storage-es megoldás és a kódból történő schema generálás annyiból is előnyösebb, hogy tovább lehet szélesíteni a támogatott adatbázisok körét, pl mongoose-nál vagy hasonló megoldásoknál is van egy struktúra, ami szerint rendezed az adatokat, és ez a struktúra változhat verziónként, ami szintén az adatbázis tartalmának átalakításához vezet. A liquibase csak SQL-t támogat, szóval egyáltalán nem silver bullet.
A ddd és event storage mellé cqrs, eventual consistency és microservices dukál, ami sok apró adatbázissal operál, amikre projection-el megy fel az adat. A projection-ök szűrnek domain event típusra ezért egy-egy microservice-re vonatkozó replay-kor csak a domain event-ek töredékét dolgozzák fel a microservice-hez tartozó projection-ök. Szóval a nagy adatbázis nem annyira probléma, mint elsőre tűnik, meg egyébként is, amelyik projekt ilyen technológiát használ, annál érzésem szerint nem gond a vas.
Persze továbbra sem vitatom el, hogy a monolit alkalmazásoknál nagyon hasznos a liquibase. Projekt méret függő a dolog, hogy melyik utat választod, sőt azt mondják, hogy érdemes monolittal kezdeni, és később refaktorálni ddd-re, ha már akkor a projekt, hogy kezelhetetlen. Én azért tanulgatom továbbra is a ddd-t, bár nem valószínű, hogy találkozni fogok akkora méretű projekttel valaha is, aminél indokolt lenne a használata, de ha ez a szoftverfejlesztői szakma jelenlegi csúcsa, akkor nagyon is érdekel... :-)
Én értettem elsőre is, hogy
Érdemes még megemlíteni, hogy a liquibase és a hasonló eszközök inkrementális verziózást tesznek lehetővé, vagyis alkalmasak korábbi verzión lévő adatbázis bármilyen későbbi verzióra migrálására. És ugyanezt visszafelé is. Továbbá a change-eidre tudsz CI-ból pl upgrade-rollback teszteket futtatni stb. Ez azért lényegesen több, mint amit egy forrás szintű verziókezelővel önmagában el tudsz érni.
Mi használunk domain eventeket és DB-t is, ugyanazon projecten belül. Mindkettő tökjó dolog, de azért ezek nem feltétlenül egymást helyettesítő technológiák.
Ennyi erővel egy új
Azt elismerem, hogy egy alter table gyorsabb, és ha gyorsan kell valami, akkor nem válogatunk az eszközökben.
Rollback-nél attól függ, hogy meddig tartod meg a régi adatbázist, ha sokáig, akkor elég csak a friss eventeket felvinni rá.
Szvsz, kisebb részben vannak struktúrális változások, és gyakrabban kerülnek bele új eventek és property-k a rendszerbe. Nyilván ezeket nem lehetnek visszafele kompatibilisek. A régi kódbázis jó esetben ezért figyelmen kívül hagyja őket. Ha struktúrális változás történt, pl szétszedtél egy nagy eventet több kicsire vagy átneveztél egy eventet, akkor megoldás lehet az event storage migrációja, és közben a régi és új eventek közötti átalakítás. Ez időigényes lehet, úgyhogy jobb elkerülni. Egyébként ugyanez a kérdés felmerül a liquibase-nél is, mi van akkor, ha a régi rendszerben néhány oszloppal kevesebb volt egy táblában? Törlődnek az oszlopok, és elveszik az adat?
Én nem értek egyet, szerintem helyettesíthetik egymást, de nem muszáj mindenben egyetértenünk. :-)
Ennyi erővel egy új
Mondom mindezt úgy, hogy a pet projectem milliárdos nagyságrendű események visszagörgetésén alapul.