
SQL kötegelt feldolgozás – bevezetés

Nagyobb forgalmú webhelyeken a folyamatos adatbázisműveletek nagy terhelés okoznak a kiszolgálónak. Azokat az információkat, amiktől nem függnek további műveletek és nincs szükség a pillanatnyi állapotukra késleltetett kötegelt módon is aktualizálhatjuk. Statisztikai, számláló, vagy szavazás jellegű, illetve hasonló tárolási feladatoknál az alap információ mellett további összesítéseket is nagyobb erőforrás igény néklkül rögzíthetünk. Az adatbázisba való kötegelt beírás nagyságrendekkel gyorsabb, mintha egyesével futtatnánk az SQL parancsokat, továbbá a jól szervezett összesítő táblák következtében, még gyorsabb a statisztikai információk kinyerése. A kötegelt feldolgozásból adódó erőforrás nyereséget az esetek többségében tárolt eljárásokkal, ideiglenes táblákkal és triggerekkel is el lehetne érni, azonban mivel jelenleg nincs szükség azonnal az aktuális eredményekre, sokkal egyszerűbb megvalósítás a kötegelés.
Megvalósítás
Példánkban egy oldalszámlálót készítünk. Az oldalszámláló a látogatott oldalak URL-jét, a látogatók gépének IP címét és a látogatás dátumát naplozza. Továbbá két statisztikai tábla is készül, az egyik napi, a másik havi szinten rögzíti a különféle oldalakhoz tartozó nézettséget. Mindhárom információt kötegelve készítjük és csak időszakosan aktualizáljuk az adatbázist egy szkripttel. Alapvetően két részből áll a megvalósítás, amiben a PHP osztály a kötegelt adatbázis műveletek létrehozásáért, míg a bash script a szinkronizációért felel.
Rendszerkövetelmény
Feladat megvalósításának a futtatási követelményei:
- tetszőleges adatbáziskiszolgáló (a példa MySQL 5.1-re tesztelve)
- PHP 5.x vagy nagyobb (Apache 2.x-en tesztelve)
- cron bejegyzés létrehozása
- bash szkript futtatási lehetőség
- fájl létrehozási jog a PHP kód részére
Program részei
Feladat részei:
- ./script/sqlbatcher.sh
- bash shellben futtatandó SQL feldolgozó szkript
- ./modules/CSQLBatch.php
- SQL Batch osztály
- ./index.php
- példaprogram
- ./sqlbatches/*.sql
- a batch fájlok ide generálódnak
- ./sqlbatches/archive/*.bak
- kötegelt szkriptek lefuttatás utáni archívuma
- ./sqlbatches/sqlbatch.log
- globális naplófájl SQL futási időkkel
Program működése
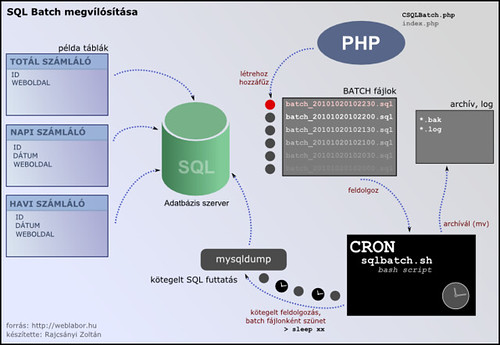
- index.php futtatása, az CSQLBatch objektum létrehozása, SQL fájlok elérési útjának a (illetve további műveletek) beállítása
- amennyiben új SQL fájl jön létre, akkor a kötegelés előtti műveletek beszúrása
- kötegelendő SQL parancsok beszúrása
- SQL fájl lezárása előtt a kötegelést befejező műveletek (ha vannak)
- shell szkript az aktuálisan éppen írás alatt lévő SQL kivételével lefuttatja a kötegelt fájlokat
- a lefuttatott kötegelt fájlok archíválása az archív könyvtárba
Adatbázis létrehozása
Az adatbázist tester néven hozom létre. Az alap naplózást a tbl_stat tábla, míg az összesítéseket a tbl_stat_daily (napi) és tbl_stat_monthly (havi) táblák látják el. Adatbázist létrehozó szkript:
CREATE DATABASE tester;
CREATE TABLE `tbl_stat` (
`id_stat` INT(11) UNSIGNED NOT NULL AUTO_INCREMENT,
`page` VARCHAR(255) NOT NULL,
`created` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
`ip_address` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (`id_stat`)
) ENGINE=MYISAM DEFAULT CHARSET=utf8;
CREATE TABLE `tbl_stat_daily` (
`id_stat_daily` INT(11) UNSIGNED NOT NULL AUTO_INCREMENT,
`page` VARCHAR(255) NOT NULL,
`cdate` DATE NOT NULL,
`counter` INT(11) UNSIGNED NOT NULL,
PRIMARY KEY (`id_stat_daily`),
UNIQUE KEY `idx_page_date` (`page`,`cdate`)
) ENGINE=MYISAM DEFAULT CHARSET=utf8;
CREATE TABLE `tbl_stat_monthly` (
`id_stat_monthly` INT(11) UNSIGNED NOT NULL AUTO_INCREMENT,
`page` VARCHAR(255) NOT NULL,
`cdate` DATE NOT NULL,
`counter` INT(11) UNSIGNED NOT NULL,
PRIMARY KEY (`id_stat_monthly`),
UNIQUE KEY `idx_page_date` (`page`,`cdate`)
) ENGINE=MYISAM DEFAULT CHARSET=utf8
A példakódok letölthetők. A téma további részei a dolgozat következő fejezeteiben kerülnek kifejtésre.
■



Az elképzelést alapvetően
Azonban lenne néhány megjegyzésem:
Ha a CRON segítségével van ütemezve a kötegelt feldolgozás, az még nem feltétlen jelent terheléscsökkenést, erre a scriptben fel kell készülni, ha a terhelése a rendszernek egyébként is jelentős, akkor a cron script még tovább növelheti azt. Ezért jobb megoldásnak gondolom, egy a háttér folyamatok futtatását végző daemon megvalósítását/bevezetését (pl.: gearman).
A másik "./sqlbatches/sqlbatch.log globális naplófájl SQL futási időkkel" jobb ha nem így logol az alkalmazás, jobb azt a rendszer (rendszergazda) gondjaira bízni és inkább syslogon keresztül (pl.: syslog-ng) logolni, mivel ez így központosítható, jobban kezelhető.
bname=`echo ${sqlfile%.*}`
Rendszergazdai hozzáállás
Egyébiránt szerény véleményem és tapasztalatom az, hogy az ilyen echo / stb forkolások annyira elhanyagolható terhelést okoznak, hogy nem biztos, hogy érdemes beáldozni az átláthatóságot a sebesség oltárán. Egy kötegelt feldolgozó programban áttolt SQL mennyiségnél észre sem veszed.
Az echo parancs a BASH
> bigyo.sql'
kuka@kuka$ bname=`echo ${sqlfile%.*}`
kuka@kuka$ echo "~$bname~"
~ize mize bigyo~
Bár a jelen szkript esetében ez tárgytalan, lévén az IFS karaktereken már a for elhasal:
biz\ basz.sql
ize\ bigyo.sql
kuka@kuka$ for sqlfile in $( ls -1 *.sql | head -n -1 ); do echo "~$sqlfile~"; done
~biz\~
~basz.sql~
echo!
És akkor tegyük tisztába a logolást is:
case "$1" in:
INFO)
L="local7.info"
;;
ERROR)
L="local7.err"
;;
esac
logger -t sqlbatch -p ${L} "$2"
# hasznalat:
# log ERROR "Hiba a vegrahajtas soran!"
}
Problémák
Ami a legsarkalatosabb pontja a dolognak, hogy az SQL limitációinak köszönhetően nagyon kevés alkalmazáslogika fér bele ebbe a rendszerbe, beleértve az alkalmazáshoz kapcsolódó, nem szintaktikai hibák kezelését is.
Ennek ellenére kíváncsian várom a folytatást, esetleg tényleg nézd meg a Kayapo által ajánlott Gearmant, nekem rengeteg munkát spórolt meg a buta ám de hatékony job queue-val.
Válaszol a szerző
Egyesével szeretnék válaszolni a meglátásaitokra:
kayapo:
Írta, hogy érdemesebb lenne daemon által a cron-al szemben futtatni a szkriptet. A meglátás helyes, egyenlőre nem volt szükségem rá, mivel a legnagyobb terhelés mellett is 250.000 művelet 0.3 másodperc alatt futott le a kötegelésből. A globális napló fájlban valóban logikusabb lenne naplózni, vagy legalább állíthassa be a programozó, hogy hova szeretné.
Kuka:
Írta, hogy a schell script nem elég optimailizált, illetve az időzítő résznél kissé elbonyolított. Valóban igaza van, úgyhogy érdemes lesz ezt a ráncfelvarrást elvégezni. A fájlok nevéből adódó erőforrás igénynél azt se felejtsük el, hogy nem mindenki ért a szkript készítéshez. A fejléc konfigurálhatóságának az érthetőségét fontosabbnak találtam, az erőforrás igényeknél.
Proclub:
Írta, hogy nagyon egyszerű alkalmazás logikáról van szó, azaz összetettebb dolgokat ezzel így nem lehet készíteni. A feladat valóban erről szól, talán nem annyira emeltem ki eddig a cikkben. Úgy gondolom, hogy a Keyapo által javasolt Gearman daemon kezelővel és nélküle is érdemes egy-egy gondolatot szentelni majd erre a cikkre.
ZÁRSZÓ:
Látom, hogy többen is érdeklődtök a cikk után. Szerintem jobban feldolgozható az anyag az egyszerű és mindenki által ismert cron deemon-nal. Nem tudom van e jelentkező, de szívesen készítenék egy angol-magyar publikációt weblabor kontra phpclasses.org ebben a témában. Szóval írjatok, aki benne lenne.